

1. 脏数据页到底为什么会脏?
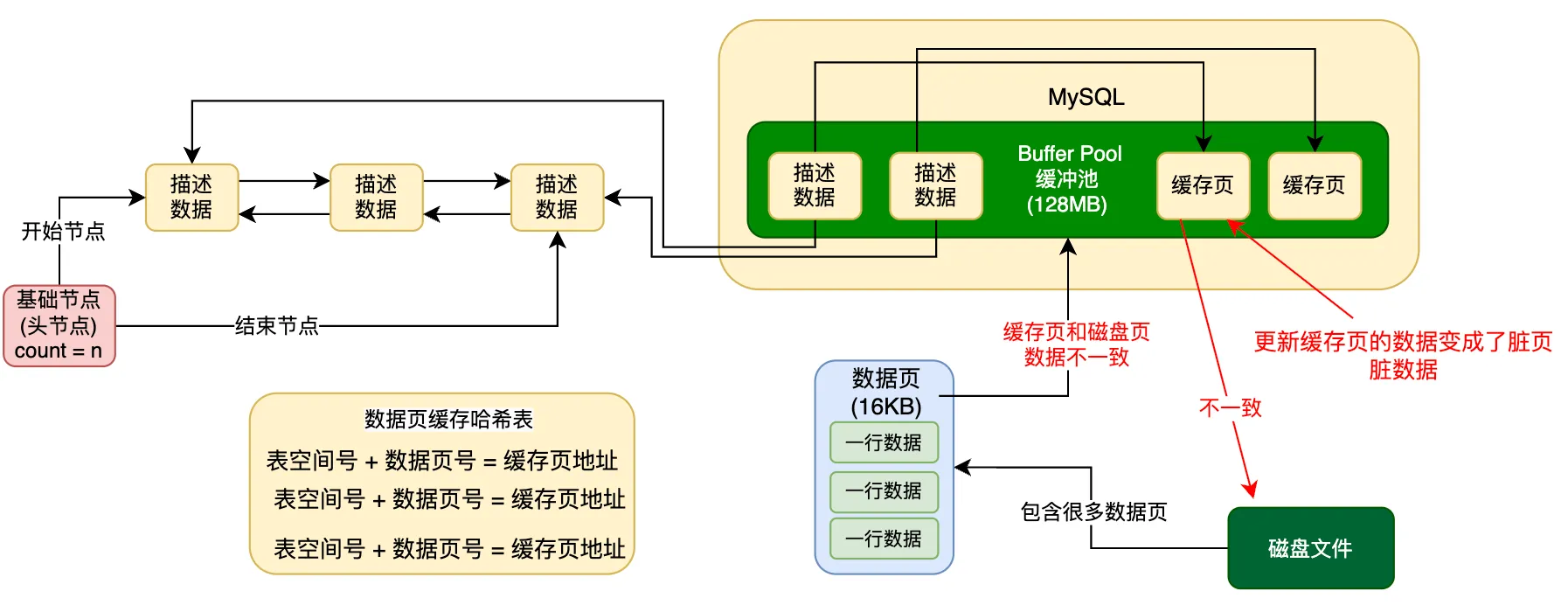
接下来,我们来探讨一个关键问题。当你在执行增、删、改操作时,如果发现数据页尚未缓存,系统就会通过 free 链表找到一个空闲的缓存页,并将数据页从磁盘读取到该缓存页中。而如果数据页已经存在于缓存中,那么下一次访问时就会直接使用缓存页,无需再从磁盘读取。
无论是哪种情况,你需要更新的数据页都会驻留在 Buffer Pool 的缓存页中,使你能够在内存中直接执行增删改操作。
然而,当你对缓存页中的数据进行修改后,会导致缓存页中的数据与磁盘上的数据页内容出现不一致的情况。此时,我们称该缓存页为“脏页”,即缓存中的数据已被修改,但尚未同步回磁盘。
2. 哪些缓存页属于脏页呢?
在之前的学习中,我们已经了解到,所有在内存中被修改过的脏页最终都会被刷新回磁盘文件。但这里就涉及到一个问题——并不是所有的缓存页都会被刷回磁盘。因为有些缓存页只是单纯地被查询时读取到 Buffer Pool,并没有发生任何修改,自然也就不需要写回磁盘。
为了解决这个问题,数据库引入了一个与 free 链表类似的 flush 链表。它的本质同样是利用缓存页的描述数据块中的两个指针,将所有被修改过的缓存页的描述数据块串联成一个双向链表。
凡是发生过修改的缓存页,其对应的描述数据块都会被加入到 flush 链表中。flush 的含义即表示这些缓存页都是脏页,后续需要被刷新(flush)到磁盘上。
因此,flush 链表的结构与 free 链表非常相似,只不过它专门用于追踪需要写回磁盘的脏页。
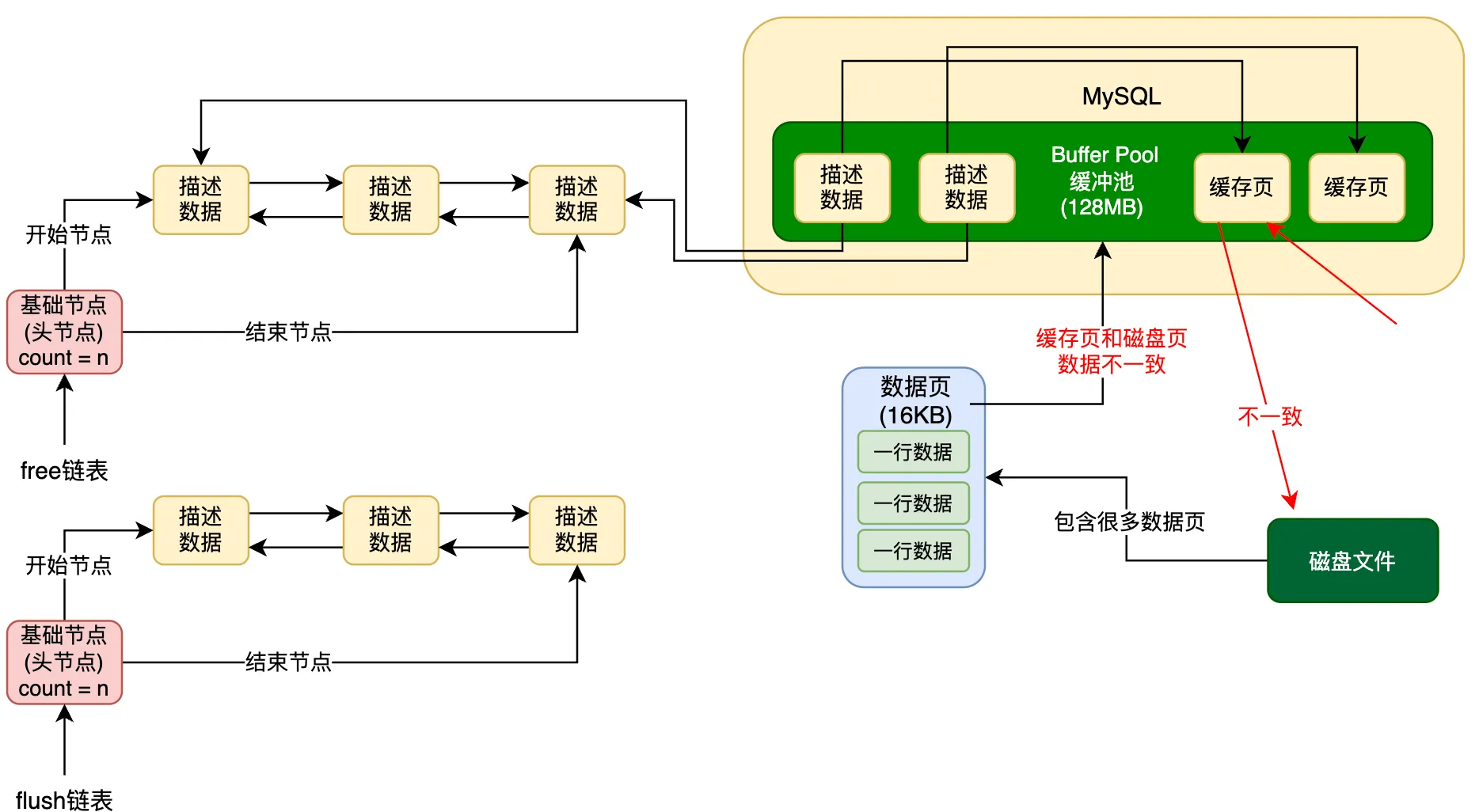
3. flush 链表构造的伪代码演示
下面我们用伪代码演示 flush 链表的构造过程。例如,当缓存页 01 的数据被修改后,它就变成了脏页,因此需要将其加入到 flush 链表中。
假设此时缓存页 01 的描述数据块如下所示:
// 描述数据块
DeccriptionDataBlock {
//这个是缓存页01的数据块
block_id = block01
int count;
free_pre = null
free_next = null
flash_pre = null
flash_next = null
}
FlashLinkListBaseNode {
start = block01
end = block01
// flush链表中有几个节点
count = 1
}我们可以看到,现在flush链表的基础节点就指向了一个block01的节点,接着比如缓存页02被更新了,他也是脏页了,此时他的描述数据块也要被加入到flush链表中去:
// 描述数据块
DeccriptionDataBlock {
//这个是缓存页01的数据块
block_id = block01
free_pre = null
free_next = null
flash_pre = null
flash_next = block02
}
DeccriptionDataBlock {
//这个是缓存页01的数据块
block_id = block02
free_pre = null
free_next = null
flash_pre = block01
flash_next = null
}
FlashLinkListBaseNode {
start = block01
end = block02
// flush链表中有几个节点
count = 2
}当更新缓存页时,可以通过调整缓存页描述数据块中的 flush 链表指针,将所有脏页的描述数据块串联成一个双向链表,即 flush 链表。此外,flush 链表的基础节点会维护头节点和尾节点的指针,以便快速定位整个链表的起始和末尾位置。
借助 flush 链表,数据库能够清晰地记录哪些缓存页已经被修改,标记为脏页,并在适当的时候将这些脏页的数据刷新回磁盘,确保数据持久化和一致性。
评论区