

Redis 中支持了多种数据类型,其中比较常用的有五种:
字符串(String)
哈希(Hash)
列表(List)
集合(Set)
有序集合(Sorted Set)/(Zset)
另外,Redis中还支持一些高级的数据类型,如:Streams、Bitmap、Geospatial以及HyperLogLog
Redis为什么要自己定义SDS?
Redis 没有直接使用 C 语言原生的字符串(char*),而是自己定义了一种更安全、更高效的字符串结构 —— SDS(Simple Dynamic String),主要原因如下:
✅ 一、C 字符串存在的缺陷
1. 无法记录字符串长度
C 字符串是以 \0 结尾的 char[]。
计算长度只能 strlen(s),时间复杂度是 O(n),每次都要遍历一遍。
2. 容易缓冲区溢出
标准 char[] 不记录容量,无法自动扩容。
稍不注意容易出现内存越界、写入溢出等严重 bug。
3. 不支持二进制安全
char* 中遇到 \0 就认为字符串结束,不能处理带有 \0 的二进制数据。
✅ 二、Redis 使用 SDS 的原因
Redis 引入 SDS(Simple Dynamic String),对上述问题进行了解决:
✅ 三、SDS 结构设计(Redis 7/8版本以 hdr5/hdr8/hdr16 等形式优化)
早期结构如下(简化版):
struct sdshdr {
int len; // 实际字符串长度
int alloc; // 分配的总空间大小(不含 header)
char buf[]; // 字符内容(不以 \0 结尾也可以)
};例如:字符串 “abc”:
len = 3
alloc = 10
buf = ['a','b','c',... ](不一定以 \0 结束)
✅ 四、SDS 优势总结一句话
SDS 提供了更高性能(O(1) 获取长度)、更安全(防止溢出)、更灵活(支持二进制数据)的字符串操作,是 Redis 高性能核心之一。
下面是 SDS(Simple Dynamic String)结构设计的演变图示,展示了 Redis 如何在不同版本中优化 SDS,以实现性能与内存的平衡。
✅ 1. 传统 C 字符串结构图(char *)
+--------------------+
| 'R' | 'e' | 'd' | 'i' | 's' | '\0' |
+--------------------+
↑
char* 指针指向首地址缺点:
没有长度字段,调用 strlen 时必须遍历;
容易内存溢出;
不支持嵌入 \0 的二进制内容。
✅ 2. Redis 早期 SDS(如 Redis 2.x/3.x)结构(sdshdr)
+---------+--------+--------+--------------------------+
| len | alloc | flags | buf[] |
+---------+--------+--------+--------------------------+
↑
实际容量 分配容量 标志位 存储内容,可能包含 '\0',可处理二进制len: 当前字符串实际长度(O(1) 访问)
alloc: 已分配的 buf 长度
flags: SDS 类型(用最低位区分 hdr5/hdr8 等)
✅ 3. Redis 4.x+ 引入多种变体结构(节省内存)
Redis 根据字符串长度动态选择 header 类型:
✅ 图示:Redis SDS 的变体结构图 sdshdr8
示例(常用结构):
+----------+----------+--------+---------------------------+
| len(1B) | alloc(1B)| flags | buf[] |
+----------+----------+--------+---------------------------+
↑
实际内容长度为 len,容量为 allocsdshdr5
示例(超短字符串):
+--------+------------------+
| flags | buf[] |
+--------+------------------+
↑
len 存在 flags 中高 5 位,类型存在低 3 位✅ 总结对比图
Redis中的Zset是怎么实现的?
ZSet(也称为Sorted Set)是Redis中的一种特殊的数据结构,它内部维护了一个有序的字典,这个字典的元素中既包括了一个成员(member),也包括了一个double类型的分值(score)。这个结构可以帮助用户实现记分类型的排行榜数据,比如游戏分数排行榜,网站流行度排行等。
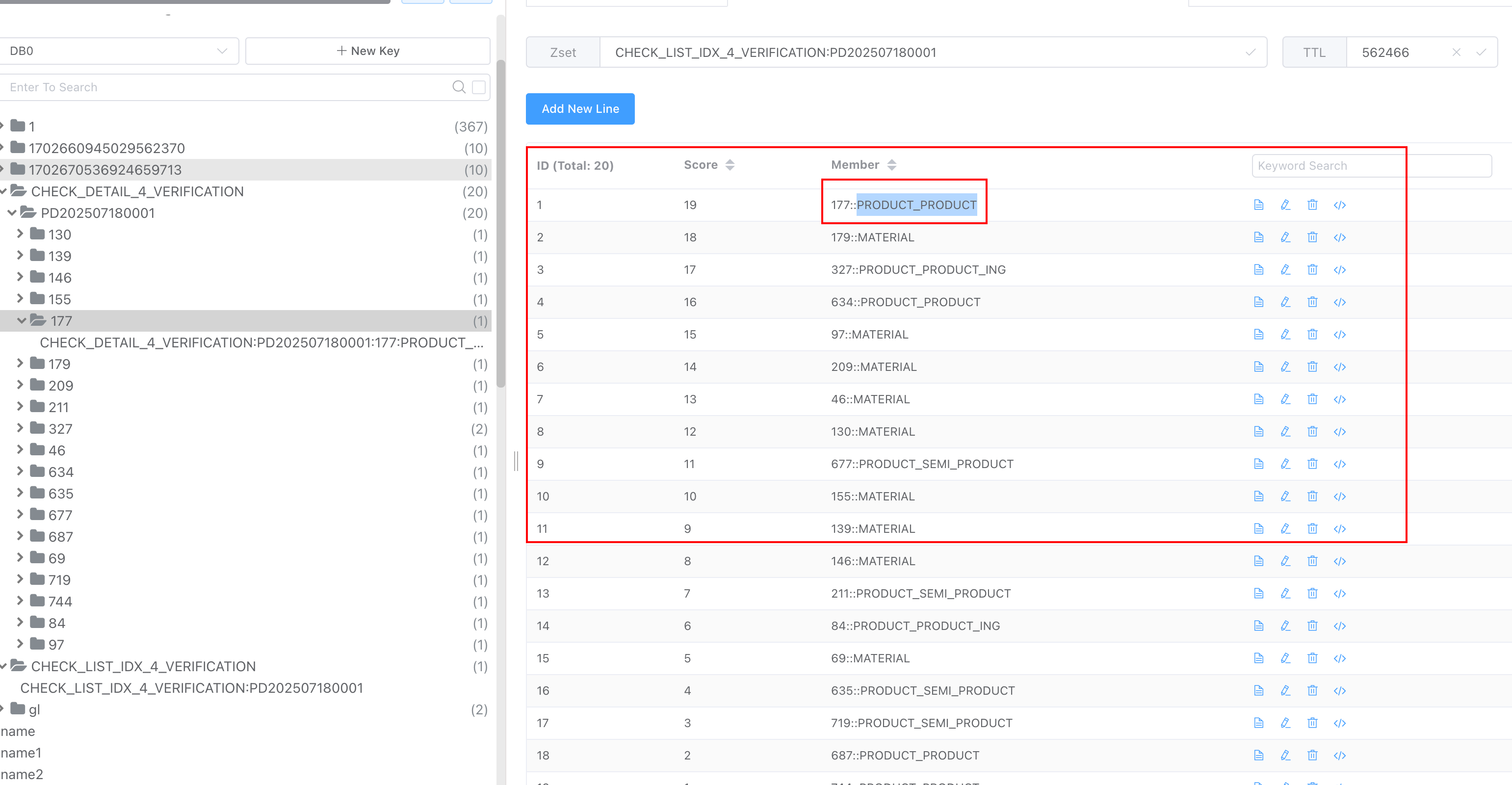
Redis中的ZSet在实现中,有多种结构,大类的话有两种,分别是ziplist(压缩列表)和skiplist(跳跃表),但是这只是以前,在Redis 5.0中新增了一个listpack(紧凑列表)的数据结构,这种数据结构就是为了替代ziplist的,而在之后Redis 7.0的发布中,在Zset的实现中,已经彻底不再使用zipList了。
当ZSet的元素数量比较少时,Redis会采用ZipList(ListPack)来存储ZSet的数据。ZipList(ListPack)是一种紧凑的列表结构,它通过连续存储元素来节约内存空间。当ZSet的元素数量增多时,Redis会自动将ZipList(ListPack)转换为SkipList,以保持元素的有序性和支持范围查询操作。
在这个过程中,Redis会遍历ZipList(ListPack)中的所有元素,按照元素的分数值依次将它们插入到SkipList中,这样就可以保持元素的有序性。
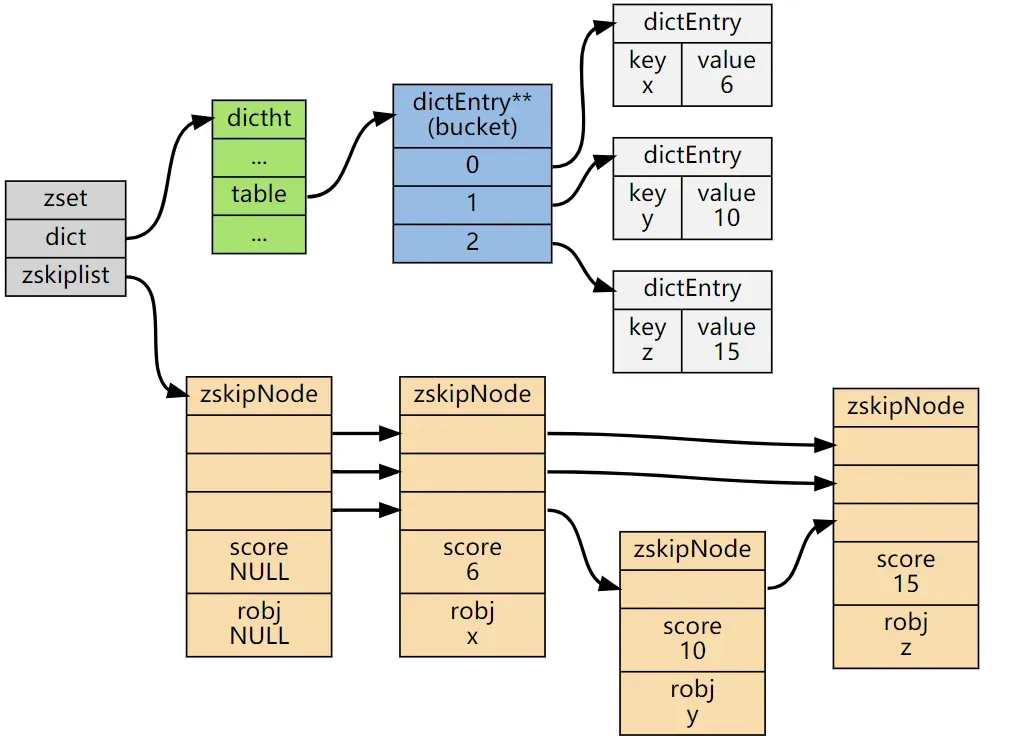
在Redis的ZSET具体实现中,SkipList的这种实现,不仅用到了跳表,还会用到dict(字典)
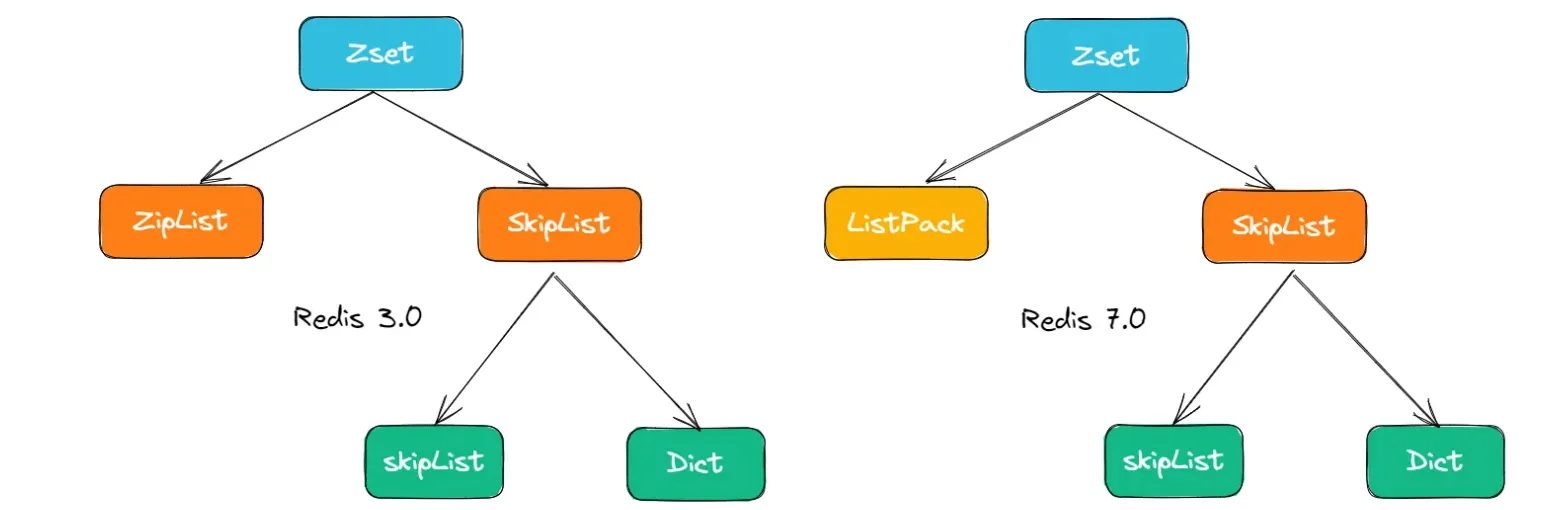
其中,SkipList用来实现有序集合,其中每个元素按照其分值大小在跳表中进行排序。跳表的插入、删除和查找操作的时间复杂度都是 O(log n),可以保证较好的性能。
dict用来实现元素到分值的映射关系,其中元素作为键,分值作为值。哈希表的插入、删除和查找操作的时间复杂度都是 O(1),具有非常高的性能。
ListPack 和 SkipList何时转换?
ZipList(ListPack)和SkipList之间是什么时候进行转换的呢?
在 Redis 中,ZSET在特定条件下会使用 ziplist作为其内部表示。这通常发生在有序集合较小的时候,具体条件如下:
元素数量少:集合中的元素数量必须小于某个阈值(zset-max-ziplist-entries)。
元素大小小:集合中的每个元素(包括值和分数)的大小必须小于指定的最大值(zset-max-ziplist-value)。
默认情况下,zset-max-ziplist-entries是128,zset-max-ziplist-value是64。
总的来说就是,当元素数量少于128,每个元素的长度都小于64字节的时候,使用ZipList(ListPack),否则,使用SkipList!
跳表
跳表也是一个有序链表,如下面这个数据结构:

在这个链表中,我们想要查找一个数,需要从头结点开始向后依次遍历和匹配,直到查到为止,这个过程是比较耗费时间的,他的时间复杂度是0(n)。
当我们想要向这个链表中插入一个数的时候,过程和查找类似,先需要从头开始遍历找到合适的为止,然后再插入,他的时间复杂度也是 O(n)。
那么,怎么能提升遍历速度呢,有一个办法,那就是我们对链表进行改造,先对链表中每两个节点建立第一级索引,如下图所示:
有了我们创建的这个索引之后,我们查询元素12,我们先从一级索引6 -> 9 -> 17 -> 26中查找,发现12介于9和17之间,然后,转移到下一层进行搜索,即9 -> 12 -> 17,即可找到12这个节点了。
可以看到,同样是查找12,原来的链表需要遍历5个元素(3、6、7、9、12),建立了一层索引之后,只需要遍历4个元素即可(6、9、17、12)。
像上面这种带多级索引的链表,就是跳表。
评论区