

Kafka 中常见的选举过程有以下几种:
Partition Leader 选举
Kafka 中的每个 Partition 都有一个 Leader,负责处理该 Partition 的读写请求。在正常情况下,Leader 和 ISR 集合中的所有副本保持同步,Leader 接收到的消息也会被 ISR 集合中的副本所接收。当 leader 副本宕机或者无法正常工作时,需要选举新的 leader 副本来接管分区的工作。
Leader 选举的过程如下:
每个参与选举的副本会尝试向 ZooKeeper 上写入一个临时节点,表示它们正在参与 Leader 选举;
所有写入成功的副本会在 ZooKeeper 上创建一个序列号节点,并将自己的节点序列号写入该节点;
节点序列号最小的副本会被选为新的 Leader,并将自己的节点名称写入 ZooKeeper 上的 /broker/.../leader 节点中。
Controller 选举
Kafka 集群中只能有一个 Controller 节点,用于管理分区的副本分配、leader 选举等任务。当一个Broker变成Controller后,会在Zookeeper的/controller节点 中记录下来。然后其他的Broker会实时监听这个节点,主要就是避免当这个controller宕机的话,就需要进行重新选举。
Controller选举的过程如下:
所有可用的 Broker 向 ZooKeeper 注册自己的 ID,并监听 ZooKeeper 中 /controller 节点的变化。
当 Controller 节点出现故障时,ZooKeeper 会删除 /controller 节点,这时所有的 Broker 都会监听到该事件,并开始争夺 Controller 的位置。
为了避免出现多个 Broker 同时竞选 Controller 的情况,Kafka 设计了一种基于 ZooKeeper 的 Master-Slave 机制,其中一个 Broker 成为 Master,其它 Broker 成为 Slave。Master 负责选举 Controller,并将选举结果写入 ZooKeeper 中,而 Slave 则监听 /controller 节点的变化,一旦发现 Master 发生故障,则开始争夺 Master 的位置。
当一个 Broker 发现 Controller 失效时,它会向 ZooKeeper 写入自己的 ID,并尝试竞选 Controller 的位置。如果他创建临时节点成功,则该 Broker 成为新的 Controller,并将选举结果写入 ZooKeeper 中。
其它的 Broker 会监听到 ZooKeeper 中 /controller 节点的变化,一旦发现选举结果发生变化,则更新自己的元数据信息,然后与新的 Controller 建立连接,进行后续的操作。
Kafka 中 Controller 选举机制 和其背后的 基于 ZooKeeper 的 Master-Slave 竞选流程,是 Kafka 高可用性设计的核心组成部分之一
✅ 一、为什么需要 Controller?
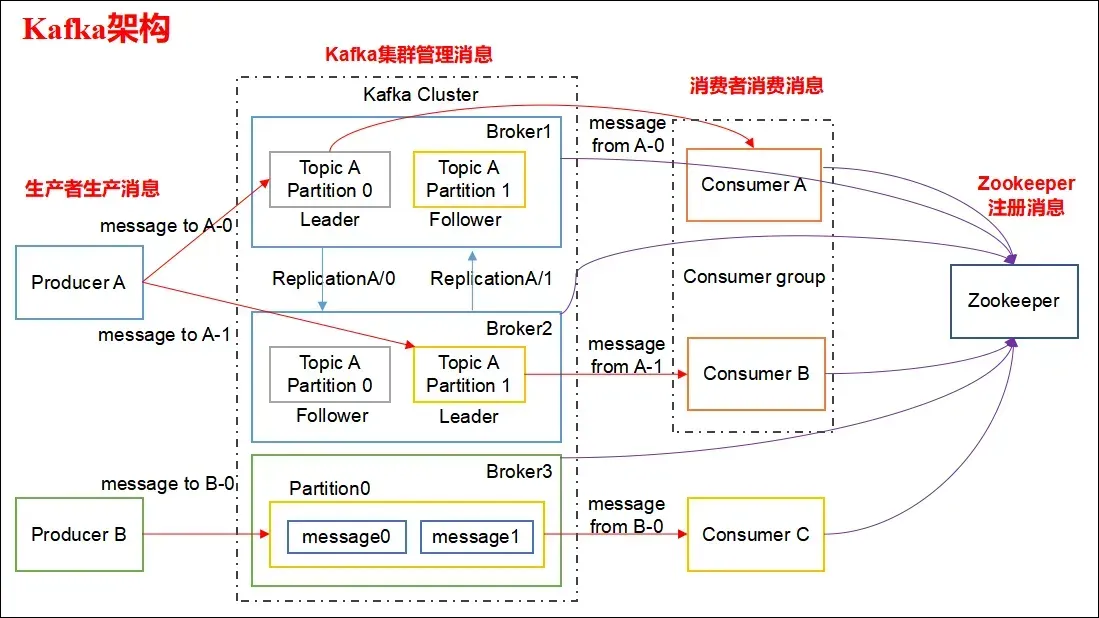
在 Kafka 中,Controller(控制器) 是一个特殊的 Broker 节点,负责整个集群的元数据管理和分区领导者选举:
Partition Leader 的选举与切换
Topic/Partition 的创建与删除
ISR(In-Sync Replica)列表的维护
Broker 增删事件监听与处理
整个 Kafka 集群 只能有一个 Controller,是 Kafka 正常运行的基础。
✅ 二、Controller 是如何选出来的?
Kafka 使用 ZooKeeper + 临时节点机制 来保证全局唯一的 Controller。
2.1 关键节点
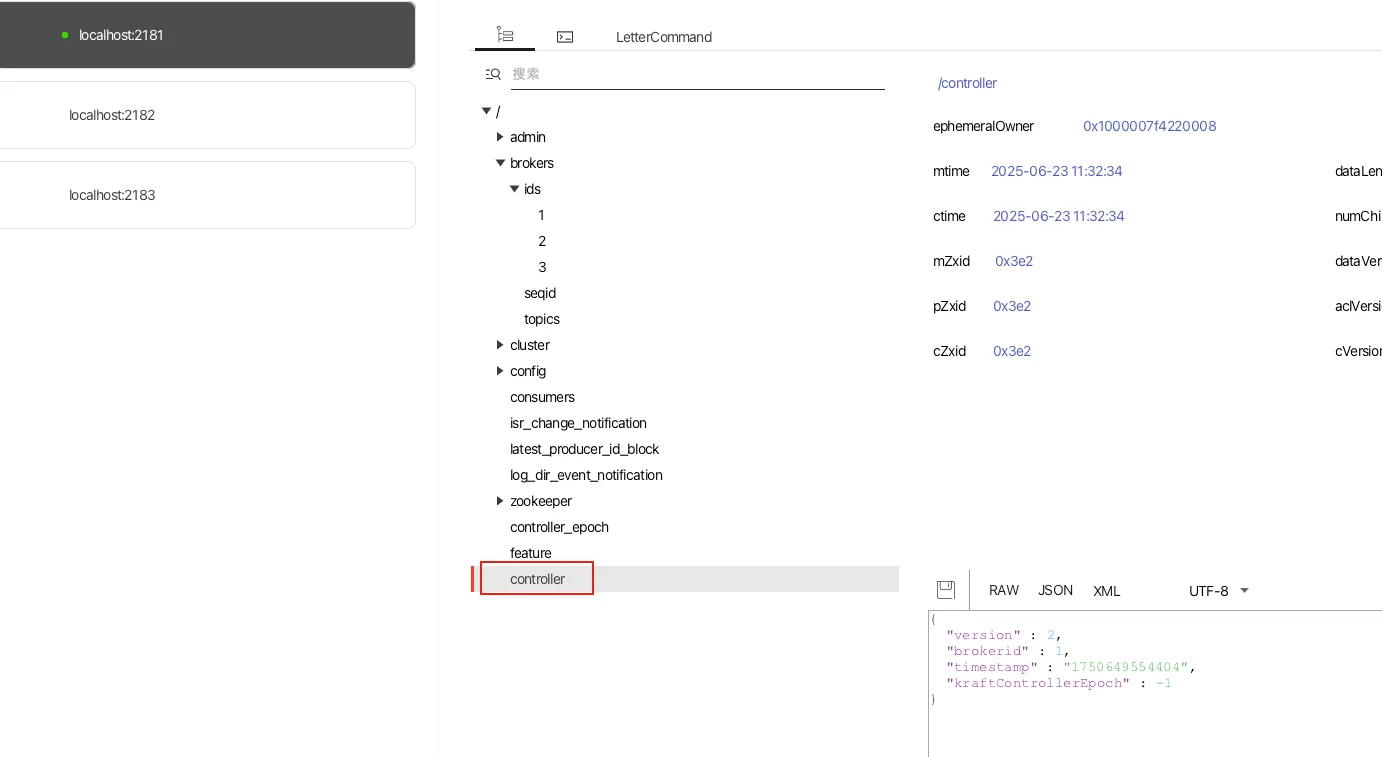
/controller:Kafka 所有 Broker 都会争抢在 ZooKeeper 中创建该临时节点(ephemeral)。
谁先成功创建该节点,谁就是 Controller。
✅ 三、完整选举流程详解
假设有 3 个 Kafka Broker:broker-1, broker-2, broker-3:
步骤 1️⃣:所有 Broker 启动,尝试竞选 Controller
每个 Broker 启动后,都会尝试在 ZooKeeper 创建 /controller 节点,内容为自身的 brokerId。
只有第一个成功创建该节点的 Broker 成为 Controller。
ZooKeeper 保证在同一时间内,只有一个客户端能成功创建某个特定的临时节点。
步骤 2️⃣:Controller 上任,开始主控工作
成功成为 Controller 的 Broker 会执行:
扫描所有 Topic 和 Partition 的元数据;
为每个 Partition 分配 Leader;
维护各 Partition 的 ISR 列表;
监听 /brokers/ids 和 /brokers/topics 节点变化,感知 Broker 上下线和 Topic 操作;
向其他 Broker 发送 LeaderAndIsrRequest,同步元数据状态。
步骤 3️⃣:其他 Broker 成为 Follower,监听 Controller 状态
所有非 Controller 的 Broker,监听 ZooKeeper 的 /controller 节点变化(即“Controller Watcher”);
一旦发现 /controller 被删除(说明 Controller 宕机),它们会重新尝试创建该节点,参与新一轮竞选。
步骤 4️⃣:Controller 故障,触发重新选举
Controller 宕机后,ZooKeeper 会自动清理它创建的临时节点 /controller;
所有 Follower Broker 被 Watch 通知,立即发起竞选;
谁先抢到 /controller 节点,谁就是新的 Controller;
新 Controller 会从 ZooKeeper 读取所有元数据并重新同步。
✅ 四、为什么说是“Master-Slave”机制?
所有 Kafka Broker 本质上是“平等的”,但在选举 Controller 的过程中:
先抢到 /controller 节点者 == 成为 Master(控制器)
其他 Broker == 成为 Slave(观察者)
这个“Master-Slave”只是暂时的控制权划分:
一旦 Master(即 Controller)宕机,Slave 会尝试升级为新的 Master。
✅ 五、故障恢复与一致性保证
ZooKeeper 的临时节点机制确保 Controller 不会“双写”;
Controller 的元数据变更都通过 ZooKeeper 保持一致;
Kafka 本身使用了 KafkaController 线程 + ZooKeeper 监听器配合协调选举。
✅ 六、Kafka 新版本变化(KRaft 模式)
自 Kafka 2.8+ 引入 KRaft(Kafka Raft Metadata Mode),Kafka 支持了 去 ZooKeeper 化架构:
不再依赖 ZooKeeper 选 Controller;
使用 Kafka 自身的 Raft 协议 实现控制器选举与元数据管理;
性能和一致性更强,架构更简洁;
推荐在 Kafka 3.x 之后采用 KRaft 模式。
✅ 七、总结重点
扩展知识
kafka选举中,为什么节点序列号最小的副本会被选为新的 Leader
在Kafka中,节点序列号最小的副本被选为新的Leader是因为Kafka使用了ZooKeeper作为其协调服务。在Kafka集群中,ZooKeeper负责维护集群的元数据(例如主题和分区信息)以及Brokers(Kafka服务器)的状态。
当一个Broker(副本)成为Leader候选人时,它会向ZooKeeper注册自己并申请成为该分区的Leader。在这个过程中,每个候选人都会创建一个临时的带有递增序列号的ZooKeeper节点,称为"选举竞争者(election contender)"。
当候选人注册完成后,它们会查询ZooKeeper并比较自己的序列号与其他候选人的序列号。Kafka采用基于递增序列号的最小值来选择新的Leader。因此,具有最小序列号的候选人将成为新的Leader,并负责处理该分区的所有读写请求。
通过这种方式,Kafka实现了简单而有效的Leader选举机制,确保了高可用性和数据一致性。选择序列号最小的副本作为Leader可以避免分区的不一致情况,并且能够快速地恢复正常操作,因为ZooKeeper节点序列号是唯一且递增的。
评论区