

XA规范
X/Open 组织(即现在的 Open Group )定义了分布式事务处理模型。 模型中主要包括
① 应用程序( AP )、
② 事务管理器( TM )、
③ 资源管理器( RM )、
④ 通信资源管理器( CRM )等四个角色。
一般,常见的事务管理器( TM )是交易中间件,常见的资源管理器( RM )是数据库,常见的通信资源管理器( CRM )是消息中间件。
通常把一个数据库内部的事务处理,如对多个表的操作,作为本地事务看待。数据库的事务处理对象是本地事务,而分布式事务处理的对象是全局事务。
所谓全局事务,是指分布式事务处理环境中,多个数据库可能需要共同完成一个工作,这个工作即是一个全局事务,例如,一个事务中可能更新几个不同的数据库。对数据库的操作发生在系统的各处但必须全部被提交或回滚。此时一个数据库对自己内部所做操作的提交不仅依赖本身操作是否成功,还要依赖与全局事务相关的其它数据库的操作是否成功,如果任一数据库的任一操作失败,则参与此事务的所有数据库所做的所有操作都必须回滚。
XA 就是 X/Open DTP 定义的交易中间件与数据库之间的接口规范(即接口函数),交易中间件用它来通知数据库事务的开始、结束以及提交、回滚等。 XA 接口函数由数据库厂商提供。
二阶提交协议和三阶提交协议就是根据这一思想衍生出来的。可以说二阶段提交其实就是实现XA分布式事务的关键。
2PC
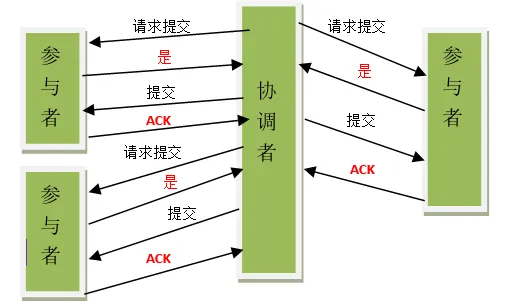
2PC存在的问题
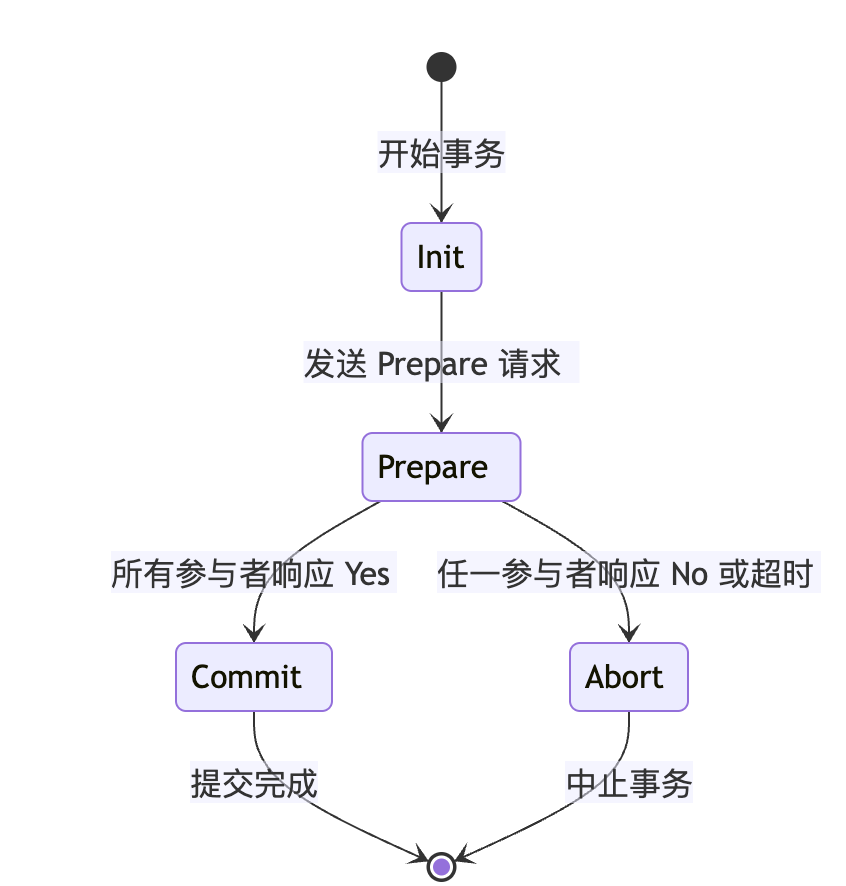
2PC 状态机图(协调者视角)
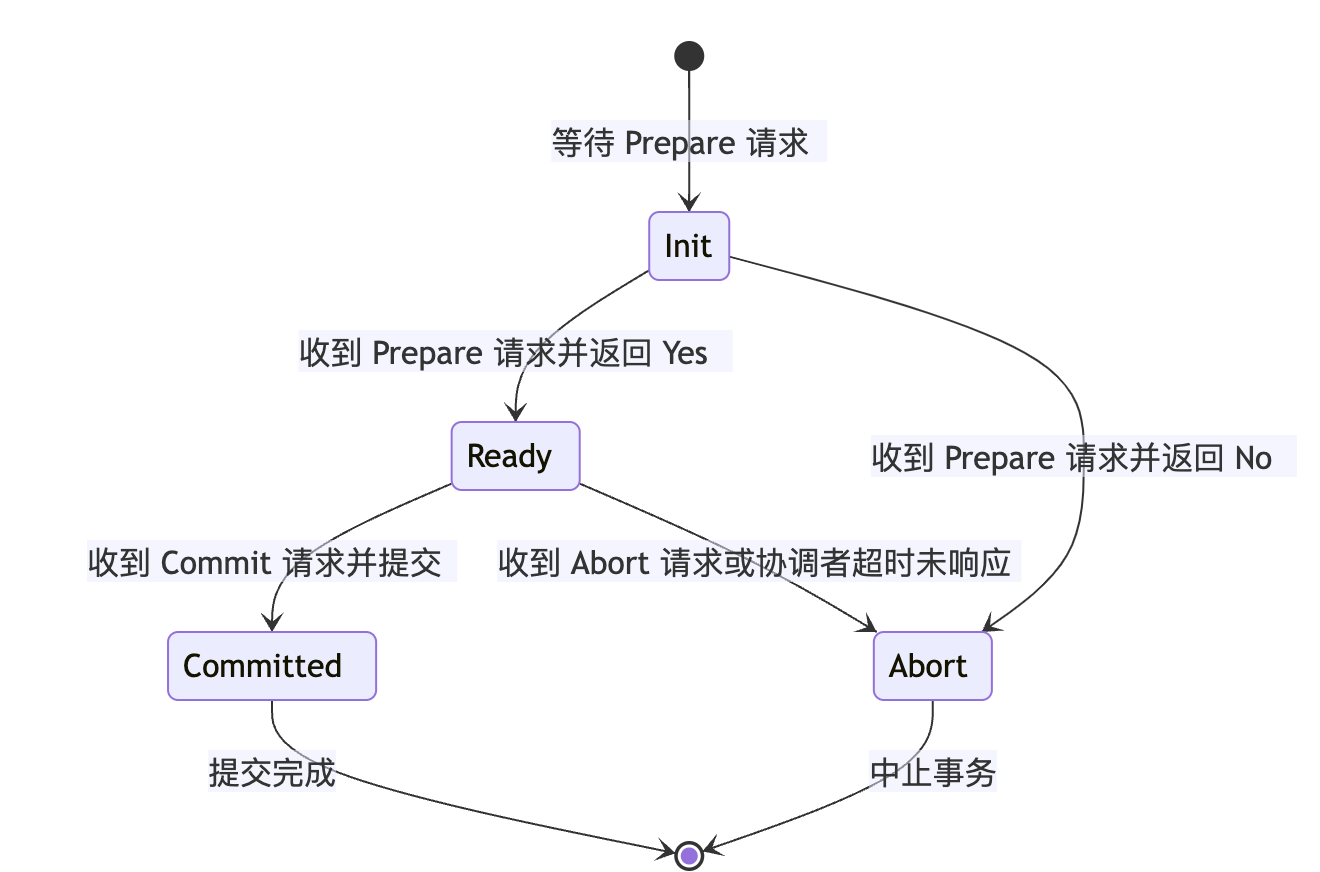
2PC 状态机图(参与者视角)
二阶段提交中,最重要的问题是可能会带来数据不一致的问题,除此之外,还存在同步阻塞以及单点故障的问题。
首先看为什么会发生同步阻塞和单点故障的问题:
1、同步阻塞问题。执行过程中,所有参与节点都是事务阻塞型的。当参与者占有公共资源时,其他第三方节点访问公共资源不得不处于阻塞状态。
2、单点故障。由于协调者的重要性,一旦协调者发生故障。参与者会一直阻塞下去。尤其在第二阶段,协调者发生故障,那么所有的参与者还都处于锁定事务资源的状态中,而无法继续完成事务操作。(如果是协调者挂掉,可以重新选举一个协调者,但是无法解决因为协调者宕机导致的参与者处于阻塞状态的问题)
作为一个分布式的一致性协议,我们主要关注他可能带来的一致性问题的。2PC在执行过程中可能发生协调者或者参与者突然宕机的情况,在不同时期宕机可能有不同的现象。
情况一:协调者挂了,参与者没挂
这种情况其实比较好解决,只要找一个协调者的替代者。当他成为新的协调者的时候,询问所有参与者的最后那条事务的执行情况,他就可以知道是应该做什么样的操作了。所以,这种情况不会导致数据不一致。
情况二:参与者挂了,协调者没挂
这种情况其实也比较好解决。如果参与者挂了。那么之后的事情有两种情况:
第一个是挂了就挂了,没有再恢复。那就挂了呗,反正不会导致数据一致性问题。
第二个是挂了之后又恢复了,这时如果他有未执行完的事务操作,直接取消掉,然后询问协调者目前我应该怎么做,协调者就会比对自己的事务执行记录和该参与者的事务执行记录,告诉他应该怎么做来保持数据的一致性。
情况三:参与者挂了,协调者也挂了(同时宕机或部分宕机)
这种情况比较复杂,我们分情况讨论。
✅ 场景一: 协调者和参与者在第一阶段挂了。
由于这时还没有执行commit操作,新选出来的协调者可以询问各个参与者的情况,再决定是进行commit还是rollback。因为还没有commit,所以不会导致数据一致性问题。
✅ 场景二:协调者在第二阶段尚未完全发送完成 commit 就宕机,部分参与者已收到 commit 并提交,部分还没收到
所有参与者已经在第一阶段 prepare 成功
协调者开始发出 commit 指令
假设 A、B 两个参与者:
A 收到 commit,成功提交本地事务
B 尚未收到 commit(或在收到之前宕机)
然后协调者也宕机,B 也宕机(或者没收到 commit 指令就崩了)
系统重启后:
A 的数据已经提交
B 不知道要 commit 还是 rollback,因为它没有收到协调者的决策,也没有自己的 commit 日志
此时协调者的日志如果丢失或无法恢复,系统无法一致达成结果
🔴 结果:数据不一致(A 提交了,B 没提交)
✅ 场景三:协调者持久化了 commit 决议,但在广播时宕机 + 参与者未持久 commit 日志
类似于上面,但变种是 协调者决定 commit 但没来得及广播 commit 指令给所有参与者 就崩溃,这时:
某些参与者可能认为一直卡在 prepare 状态
某些参与者在没有收到协调者重发的 commit 指令之前,不敢自行 commit,也不敢 rollback
🔴 如果协调者宕机后无法恢复决议状态,某些参与者永远挂在“未决状态”,系统一致性受损
所以,2PC协议中,如果出现协调者和参与者都挂了的情况,有可能导致数据不一致。
为了解决这个问题,衍生出了3PC。我们接下来看看3PC是如何解决这个问题的。
3PC
3PC最关键要解决的就是协调者和参与者同时挂掉的问题,所以3PC把2PC的准备阶段再次一分为二,这样三阶段提交就有CanCommit、PreCommit、DoCommit三个阶段。
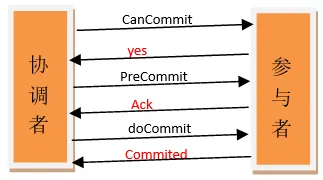
在第一阶段,只是询问所有参与者是否可以执行事务操作,并不在本阶段执行事务操作。当协调者收到所有的参与者都返回YES时,在第二阶段才执行事务操作,然后在第三阶段在执行commit或者rollback。
3PC 状态机图(协调者视角)
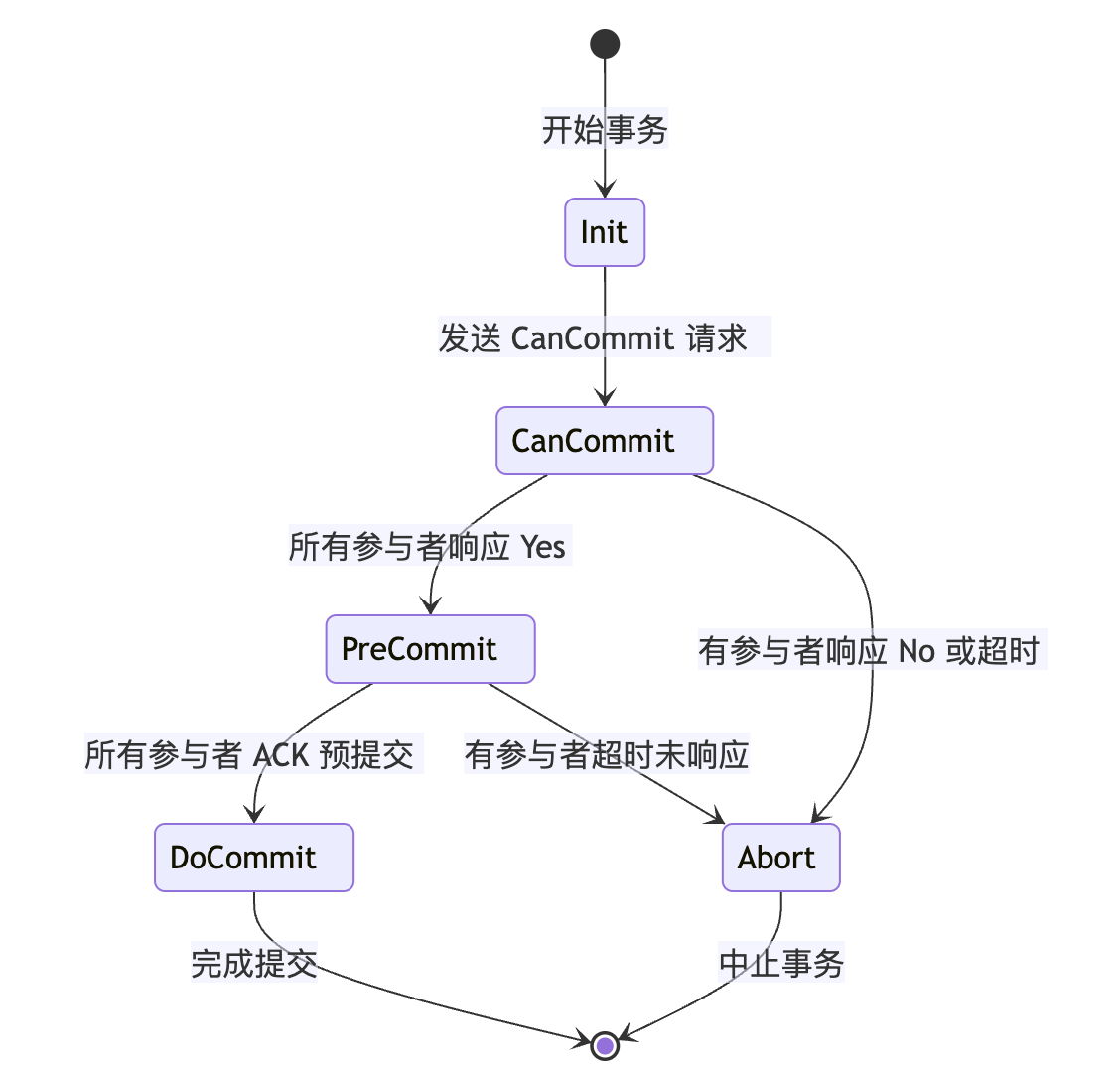
3PC 状态机图(参与者视角)
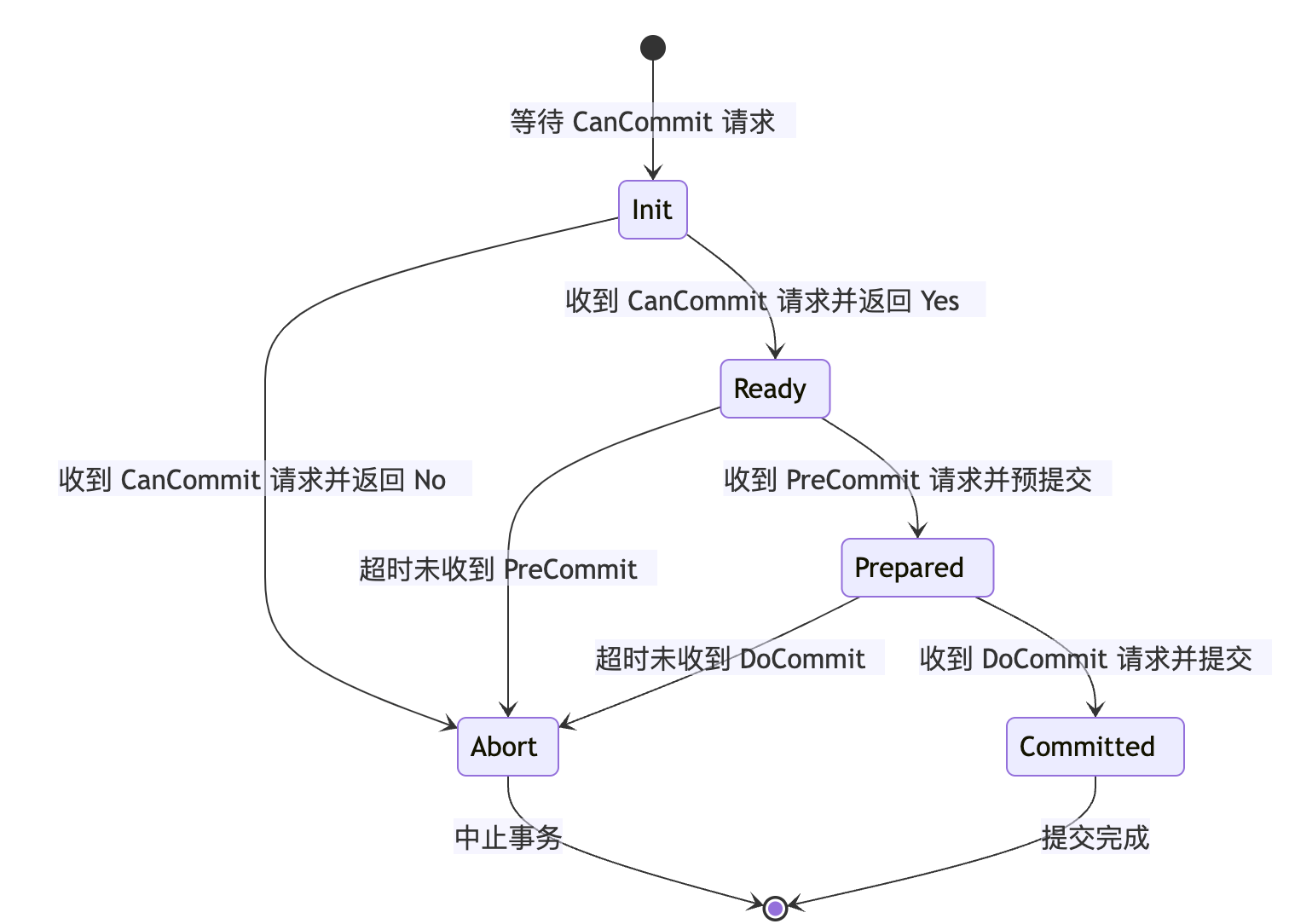
3PC为什么比2PC好?
直接分析前面我们提到的协调者和参与者都挂的情况。
第二阶段协调者和参与者挂了,挂了的这个参与者在挂之前已经执行了操作。但是由于他挂了,没有人知道他执行了什么操作。
这种情况下,当新的协调者被选出来之后,他同样是询问所有的参与者的情况来决定是commit还是rollback。这看上去和二阶段提交一样啊?他是怎么解决一致性问题的呢?
看上去和二阶段提交的那种数据不一致的情况的现象是一样的,但仔细分析所有参与者的状态的话就会发现其实并不一样。
我们假设挂掉的那台参与者执行的操作是commit。那么其他没挂的操作者的状态应该是什么?他们的状态要么是prepare-commit要么是commit。因为3PC的第三阶段一旦有机器执行了commit,那必然第一阶段大家都是同意commit。所以,这时,新选举出来的协调者一旦发现未挂掉的参与者中有人处于commit状态或者是prepare-commit的话,那就执行commit操作。否则就执行rollback操作。这样挂掉的参与者恢复之后就能和其他机器保持数据一致性了。
简单概括一下就是,如果挂掉的那台机器已经执行了commit,那么协调者可以从所有未挂掉的参与者的状态中分析出来,并执行commit。如果挂掉的那个参与者执行了rollback,那么协调者和其他的参与者执行的肯定也是rollback操作。
所以,再多引入一个阶段之后,3PC解决了2PC中存在的那种由于协调者和参与者同时挂掉有可能导致的数据一致性问题。
3PC存在的问题
在doCommit阶段,如果参与者无法及时接收到来自协调者的doCommit或者abort请求时,会在等待超时之后,会继续进行事务的提交。
所以,由于网络原因,协调者发送的abort响应没有及时被参与者接收到,那么参与者在等待超时之后执行了commit操作。这样就和其他接到abort命令并执行回滚的参与者之间存在数据不一致的情况。
abort 请求:指协调者(Coordinator)向参与者(Participant)发送的事务中止指令
当分布式事务无法正常提交时,协调者通过abort请求通知所有参与者回滚本地事务操作,确保数据一致性。
评论区