

1. 基于冷热数据分离的思想设计LRU链表
解决LRU链表问题:冷热数据分离的思想
为了优化之前讲到的 简单LRU链表 的问题,MySQL 在设计 LRU链表 时,引入了 冷热数据分离 的思想。
之前提到的一系列问题,本质上就是因为 所有缓存页都混杂在一个LRU链表里,导致了一些不合理的淘汰和预读数据页的冲突。
为了解决这个问题,MySQL 将 LRU链表 拆分成了两个部分:
热数据(频繁被访问的数据)
冷数据(很少被访问的数据)
这个冷热数据的比例是通过参数 innodb_old_blocks_pct 来控制的,默认值是 37,也就是说 冷数据占比 37%。
1.1. LRU链表的拆分
经过拆分后,LRU链表的结构会看起来像这样:
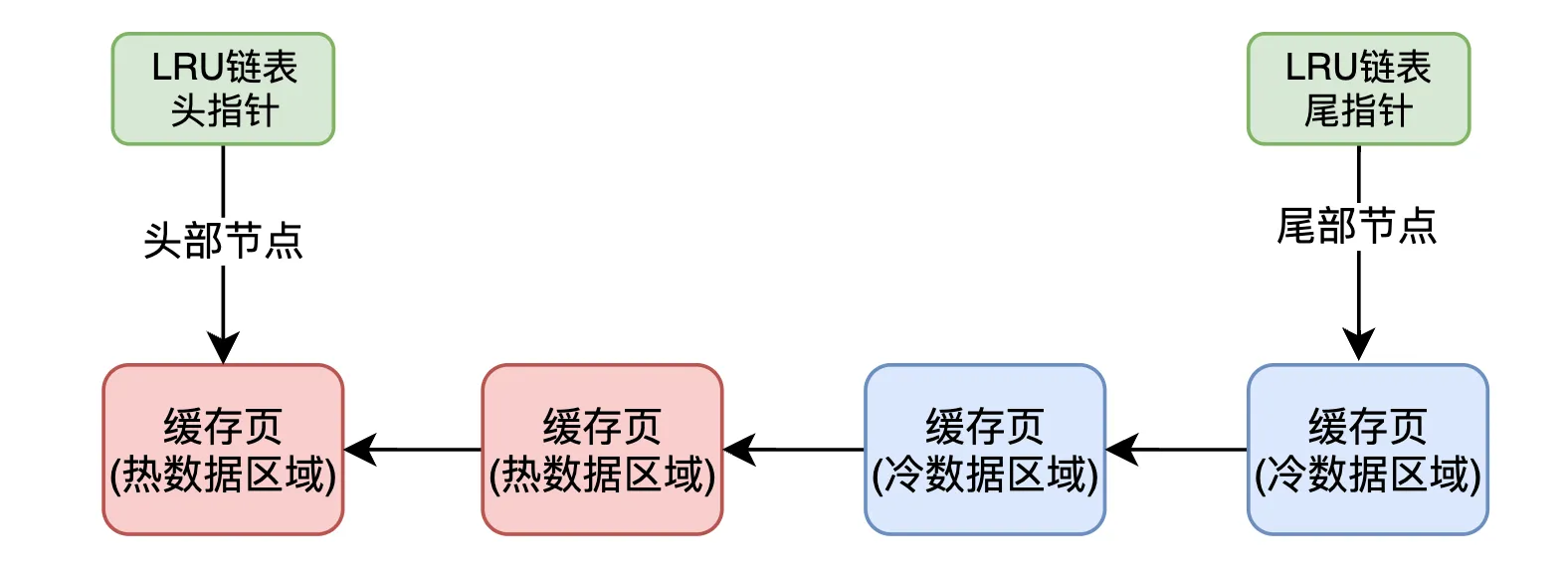
热数据部分:包含了最近频繁访问的数据,这部分数据会优先保留在缓存中,且LRU的淘汰机制也只会优先作用在那些不常访问的数据上。
冷数据部分:包含了那些很少访问的数据。这些数据会被移到一个专门的冷数据链表中,LRU淘汰时,冷数据的淘汰优先级较高。
1.2. 为什么要拆分?
减少误淘汰:通过冷热数据分离,频繁被访问的热数据不会被不合理地淘汰。冷热数据的分开管理,确保了 MySQL 能够更加智能地处理缓存页的更新和淘汰。
优化性能:对热数据和冷数据分别管理,可以在保证性能的同时减少无效的数据读写,避免冷数据占用大量缓存资源,导致热数据的缓存淘汰。
2. 数据页第一次加载到缓存时的位置
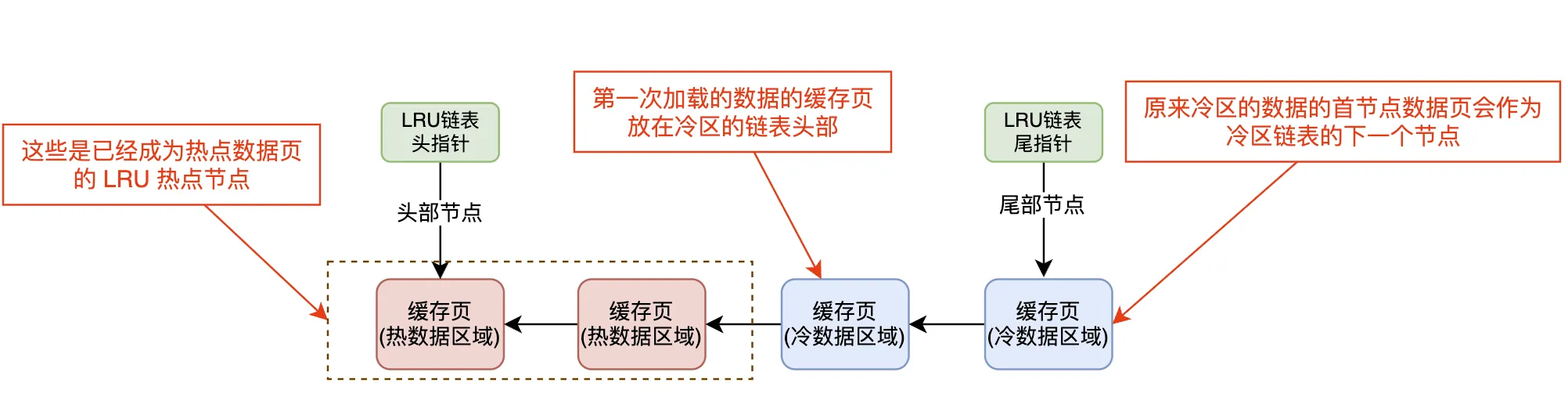
当数据页第一次被加载到 Buffer Pool 中时,它会被放置在 LRU链表冷数据区域的链表头部。
2.1. 为什么这么设计?
冷数据区:刚加载的数据页一般都还没有被频繁访问,因此它们被视作冷数据,并放在冷数据区域的链表头部。
优先淘汰冷数据:由于冷数据通常不常用,将其放在冷数据区域的头部可以确保它们在内存不足时最先被淘汰。
2.2. 过程描述
数据页加载:当一个数据页从磁盘加载到 Buffer Pool 中时,它会首先被归入冷数据区域。
冷数据区域链头:此时该数据页将被放置在冷数据区域的链表头部。
访问热数据区:随着数据页被访问,这些数据页可能会从冷数据区移到热数据区,从而变得更常用。
2.3. 目的
避免无效淘汰:通过把新加载的页放到冷数据区,系统不会因为加载新的数据页而错误地淘汰掉频繁使用的数据。
冷数据优先淘汰:将冷数据置于链头,使得当内存不足时,冷数据可以被优先淘汰,确保热数据更长时间地留在缓存中。
2.4. ⚠️⚠️⚠️注意:
InnoDB确实将LRU链表分成了两部分:New Sublist(热区)和Old Sublist(冷区)。两个部分是逻辑上的两个部分,不是两个 LRU 链表。
当新页被加入到缓冲池时,并不是直接放到热区的头部,而是先插入到冷区的头部(即整个LRU链表的5/8处,具体比例可能根据配置不同 4.1 innodb_old_blocks_time 参数)。这样可以避免短时间内大量新页冲掉热区的数据。
根据 LRU 设计,当需要淘汰页面时,InnoDB会优先淘汰冷区(Old Sublist)中的页面。这是因为冷区的数据被认为是最近较少被访问的,而热区的数据则更可能被频繁访问,因此保留热区的数据有助于提高缓存命中率。
淘汰首节点还是尾节点,通常LRU算法是淘汰最近最少使用的,也就是链表末尾的节点。
在InnoDB中,冷区的页面如果长时间未被访问,会被移动到LRU链表的尾部,最终被淘汰。热区的页如果被访问,可能会被移动到热区的更前端,避免被淘汰。具体来说,当冷区的页面被访问时,它可能需要满足一定条件(比如停留时间超过innodb_old_blocks_time参数设置的时间)才会被提升到热区。
维护LRU链表的过程包括新增数据和冷热区的调整。当新数据页被读取到缓冲池时,它首先被插入到冷区的头部。如果该页在冷区停留的时间超过设定的阈值,并且在之后被再次访问,那么它会被移动到热区的头部。这有助于确保真正被频繁访问的数据保留在热区。同时,当缓冲池空间不足时,InnoDB会从LRU链表的尾部开始淘汰页面,优先淘汰冷区的页面,如果冷区没有足够的可淘汰页面,才会考虑热区的页面。
3. 🙋♂️🙋♂️🙋♂️ 冷数据区域的缓存页何时移入热数据区域?
冷数据区域的缓存页会在一定的条件下被移入热数据区域,主要取决于它们是否被频繁访问。我们来看下移入的条件和过程。
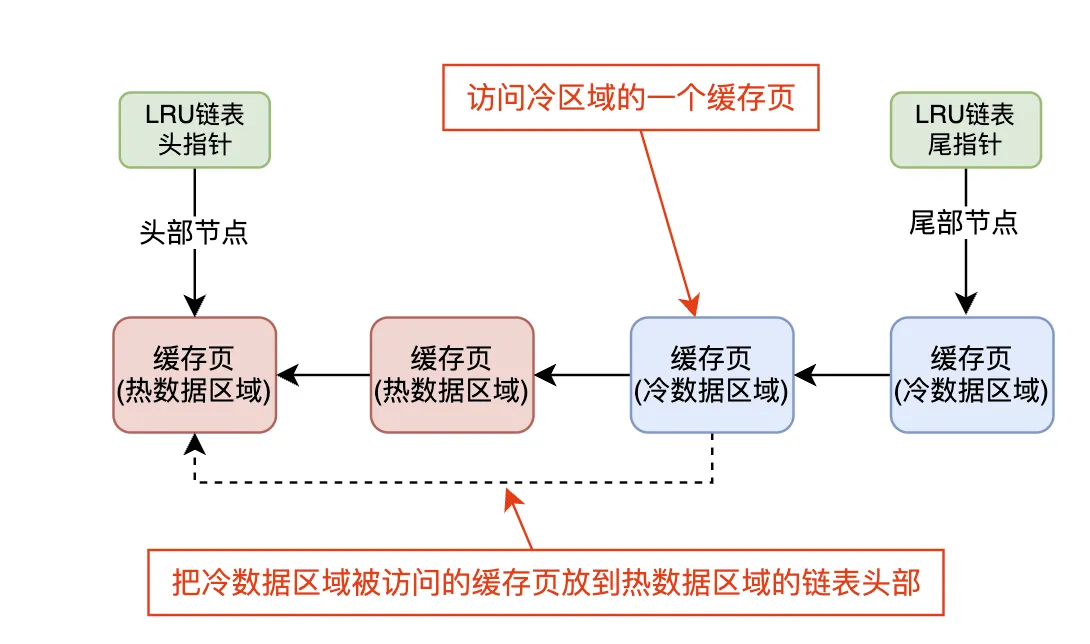
访问触发迁移
条件:当冷数据区域的缓存页被访问时,它并不会立即被移动到热数据区域的链表头部。为了防止每次访问都立刻做出迁移(这样会引起性能上的负担),会采用一定的策略,通常是访问次数或者是一定次数的访问后,才会将缓存页从冷数据区域移至热数据区域。
缓存页的访问次数
迁移的触发时机:冷数据区域中的缓存页如果被访问多次,并且这些访问频率达到一定阈值,就说明该数据已经成为热点数据,此时它就可以从冷数据区域迁移到热数据区域。通常这些缓存页会被放到热数据区域的链表头部。
策略的设计
避免频繁迁移:为了提高性能,通常会设置一个时间窗口或访问阈值,不是每次访问都进行数据迁移,而是等待某个条件满足后再移动。这避免了冷数据频繁地在热数据和冷数据区域之间切换,影响性能。
缓存页的生命周期
冷热数据区之间的动态调节:随着访问模式的变化,缓存页在热数据区域和冷数据区域之间动态调整,保证系统能够根据访问热点实时调整缓存的内容,最大化利用内存资源。
总结:
冷数据区域的缓存页会在被访问达到一定次数后,才会被移动到热数据区域,并放置在热数据区域的链表头部。这样能够确保只有被频繁访问的数据才会占用宝贵的热数据区域资源,从而提升缓存命中率和系统性能。
4. 🙋♂️🙋♂️🙋♂️冷数据区域缓存页的迁移条件
为了避免刚加载到缓存的页面立即被不合理地移到热数据区域,MySQL引入了一个时间阈值来控制冷数据到热数据的迁移。这是通过innodb_old_blocks_time参数来设置的。
4.1. innodb_old_blocks_time 参数
innodb_old_blocks_pct: 冷热链占用比例
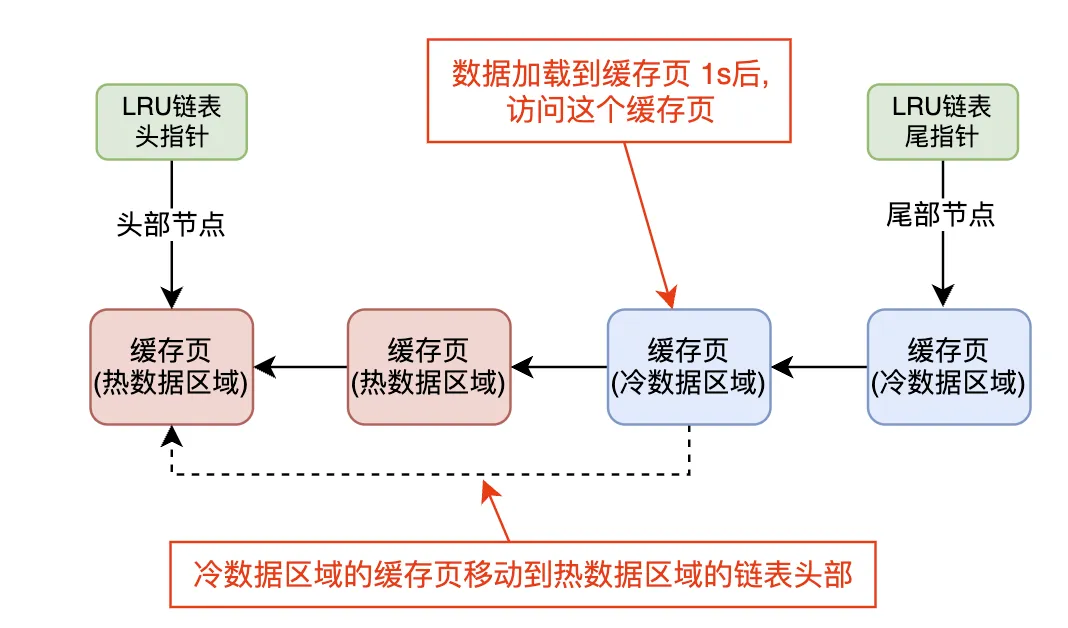
innodb_old_blocks_time: 这个参数的作用是限制冷数据区域的缓存页只能在加载到缓存页后,经过至少1秒的时间,才会根据访问情况决定是否迁移到热数据区域。
4.2. 冷数据页迁移的时机
首次加载:当一个数据页首次加载到缓存中时,它会被放在冷数据区域的链表头部。
访问后的迁移:如果该数据页在加载后超过1秒,并且在此期间被访问,那么此时它会从冷数据区域迁移到热数据区域,放置在热数据区域链表的头部。
避免短期访问:如果数据页在加载后1秒内被访问,MySQL并不会立即将其移动到热数据区域,因为这样的访问很可能只是偶然的,不代表该数据页会成为长期热数据。
4.3. 为什么要有这个时间限制?
避免短期访问的误判:如果不加时间限制,短期内的访问可能导致不必要的缓存页频繁地在冷热数据区域之间切换,增加系统的负担。通过设置1秒的时间窗口,可以更准确地判断数据页是否真正成为热点数据。
优化性能:只有在访问超过1秒后,才把数据页放入热数据区域,能够确保热数据区域的缓存页是经过一段时间验证后,真正被频繁访问的数据,避免了冷热数据的频繁迁移,提升了缓存的稳定性和性能。
4.4. 总结
冷数据区域的缓存页会在加载后至少1秒钟才会根据访问情况考虑迁移到热数据区域。这样避免了短期访问就造成不必要的迁移,确保了缓存区域的稳定性和性能。
5. 🙋♂️🙋♂️🙋♂️LRU链表的冷数据区域放的都是什么样的缓存页
总结来说,冷数据区域主要存放以下几类缓存页:
通过全表扫描或大范围扫描加载的数据页,这些页可能只会被访问一次。
预读机制加载但未被立即使用的页,尤其是线性预读的页。
从热区降级下来的页,即那些在热区中长时间未被访问,被移动到冷区尾部等待淘汰。
新加载的页但被识别为可能非热点数据,根据算法直接插入冷区。
5.1. 典型场景下的 冷区数据构成比例
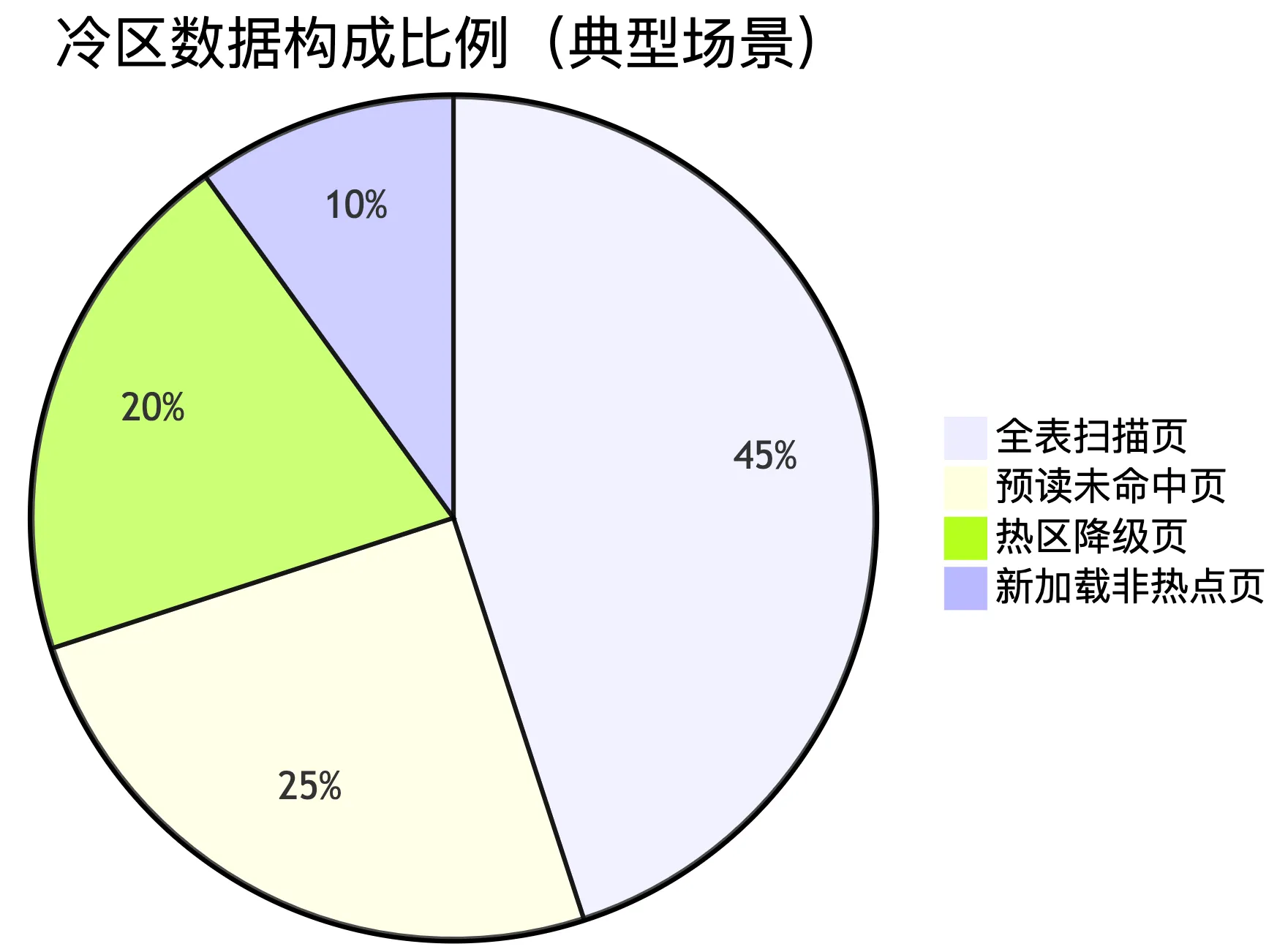
支持Mermaid图表在线测试 https://mermaid.live/
pie
title 冷区数据构成比例(典型场景)
"全表扫描页" : 45
"预读未命中页" : 25
"热区降级页" : 20
"新加载非热点页" : 10 5.2. 具体存放类别
全表扫描页
通过SELECT *等全表扫描操作加载
预读未命中页
热区降级页
迁移条件:热区页超过innodb_old_blocks_time未访问
大事务操作页
典型场景
START TRANSACTION;
UPDATE huge_table SET col = ...; -- 产生大量脏页
COMMIT;5.3. 冷区特性对比
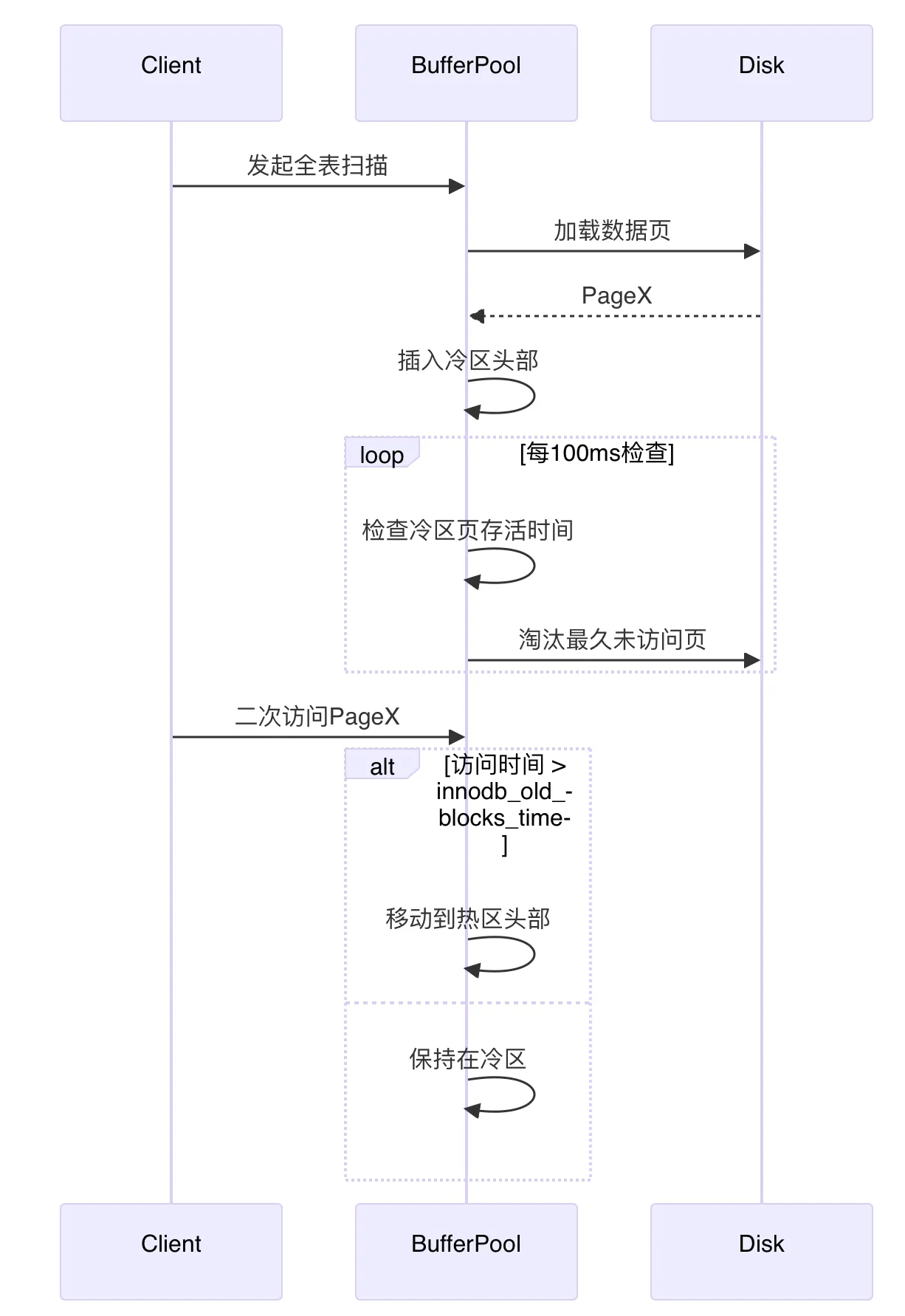
5.4. 冷区生命周期
sequenceDiagram
participant Client
participant BufferPool
participant Disk
Client->>BufferPool: 发起全表扫描
BufferPool->>Disk: 加载数据页
Disk-->>BufferPool: PageX
BufferPool->>BufferPool: 插入冷区头部
loop 每100ms检查
BufferPool->>BufferPool: 检查冷区页存活时间
BufferPool->>Disk: 淘汰最久未访问页
end
Client->>BufferPool: 二次访问PageX
alt 访问时间 > innodb_old_blocks_time
BufferPool->>BufferPool: 移动到热区头部
else
BufferPool->>BufferPool: 保持在冷区
end 使用 typora 渲染
5.5. 监控冷区状态
查看冷区比例:
SHOW VARIABLES LIKE 'innodb_old_blocks_pct';查看冷区命中率:
SHOW ENGINE INNODB STATUS\G
-- 查找如下信息:
-- Pages made young 0, not young 0
-- youngs/s 0.00 non-youngs/s 0.00关键指标说明:
Innodb_pages_made_young # 冷区晋升到热区的页数
Innodb_pages_not_made_young # 访问但未达到晋升条件的页数
Innodb_old_blocks_secs # 实际生效的old_blocks_time值6. 基于冷热数据分离方案优化后的LRU链表,是如何解决之前的问题的?
6.1. 预读机制与全表扫描对冷热数据区域的影响
当使用冷热数据分离的LRU链表机制后,预读机制和全表扫描加载进来的一大堆缓存页会被直接放置在冷数据区域的前面。这有效地解决了预读和全表扫描带来的问题,因为这些缓存页不会干扰到热数据区域中频繁被访问的缓存页。
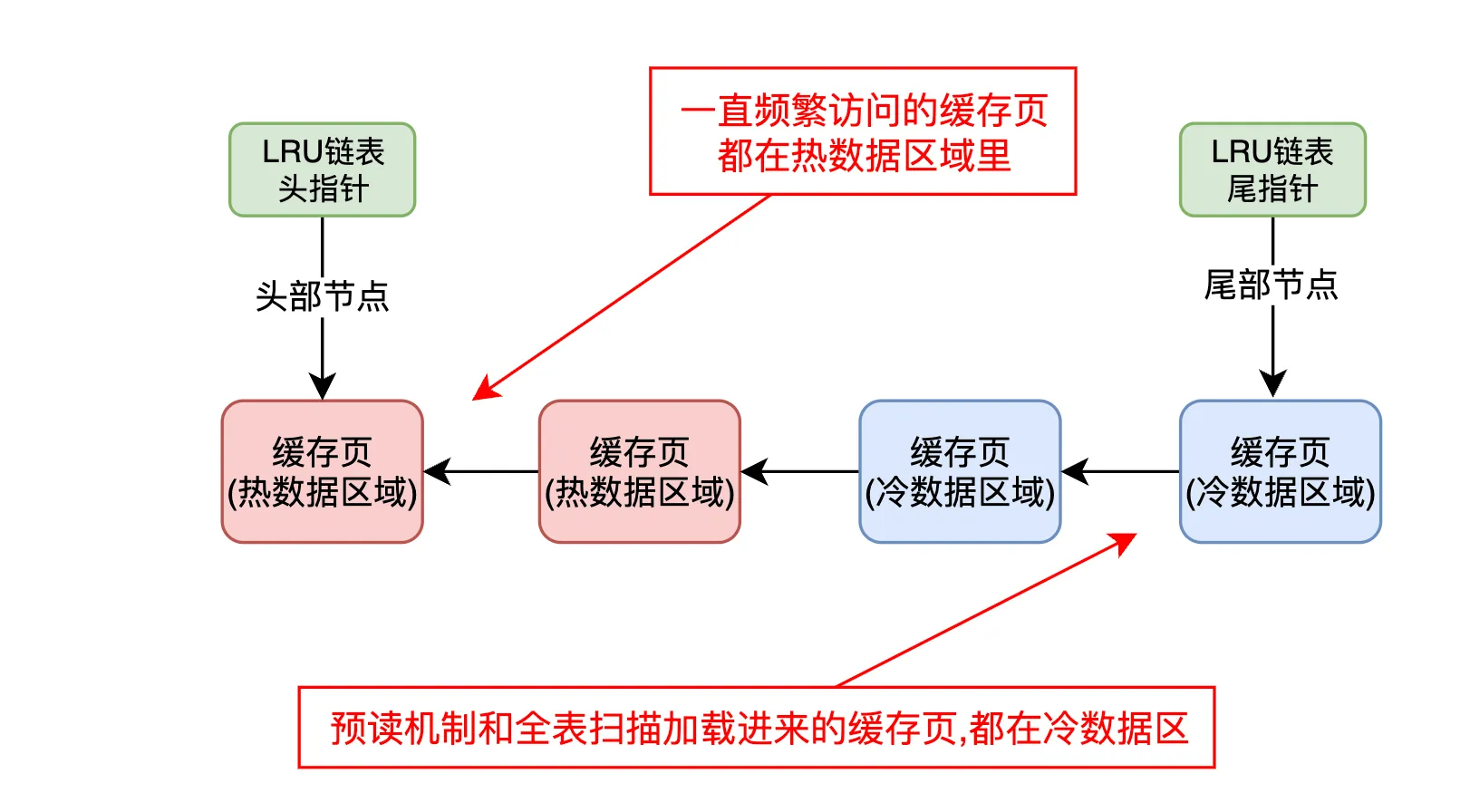
冷热数据区域的分离如何解决问题?
预读机制和全表扫描加载的缓存页
预读和全表扫描通常会一次性加载大量相邻的数据页,这些数据页可能根本不会被频繁访问。
在冷热数据分离的LRU链表中,这些缓存页会被放到冷数据区域,而不是和频繁访问的缓存页混在一起。
由于冷数据区域存放的是长时间未被访问的数据页,所以这些不常用的缓存页会在冷数据区域中停留,不会影响热数据区域。
除非在冷数据区域里的缓存页,在1s之后还被人访问了,那么此时他们就会判定为未来可能会被频繁访问的缓存页,然后移动到热数据区域的链表头部去!
热数据区域的缓存页
热数据区域依然保持着频繁被访问的缓存页,这些缓存页会一直保持在热数据区域的链表头部。
如果缓存页被访问,它会被移动到热数据区域的链表头部,确保最常访问的数据始终保持在缓存中。
效果
隔离冷数据和热数据:冷数据区域和热数据区域的缓存页不互相影响,避免了预读和全表扫描加载的冷数据占用热数据区域的空间。
提高缓存的效率:频繁访问的数据可以始终保持在热数据区域,减少了频繁被访问的缓存页被淘汰的概率,提高了缓存命中率。
降低不必要的磁盘I/O:通过有效隔离不常访问的数据页,MySQL可以在需要淘汰缓存页时,更加精准地选择冷数据区域中的数据进行淘汰,而不是将热数据误淘汰。
总结
通过冷热数据分离的LRU链表,MySQL有效地将预读和全表扫描加载的缓存页隔离到冷数据区域,避免了这些缓存页与频繁访问的缓存页混合,提升了缓存管理的效率,确保了热数据区域中的数据始终是最常访问的,从而优化了系统的性能和响应速度。
6.2. 缓存页不足时的淘汰策略
当缓存页不足时,MySQL会根据冷热数据区域的分离策略来决定哪些缓存页需要被淘汰。具体的淘汰过程如下:
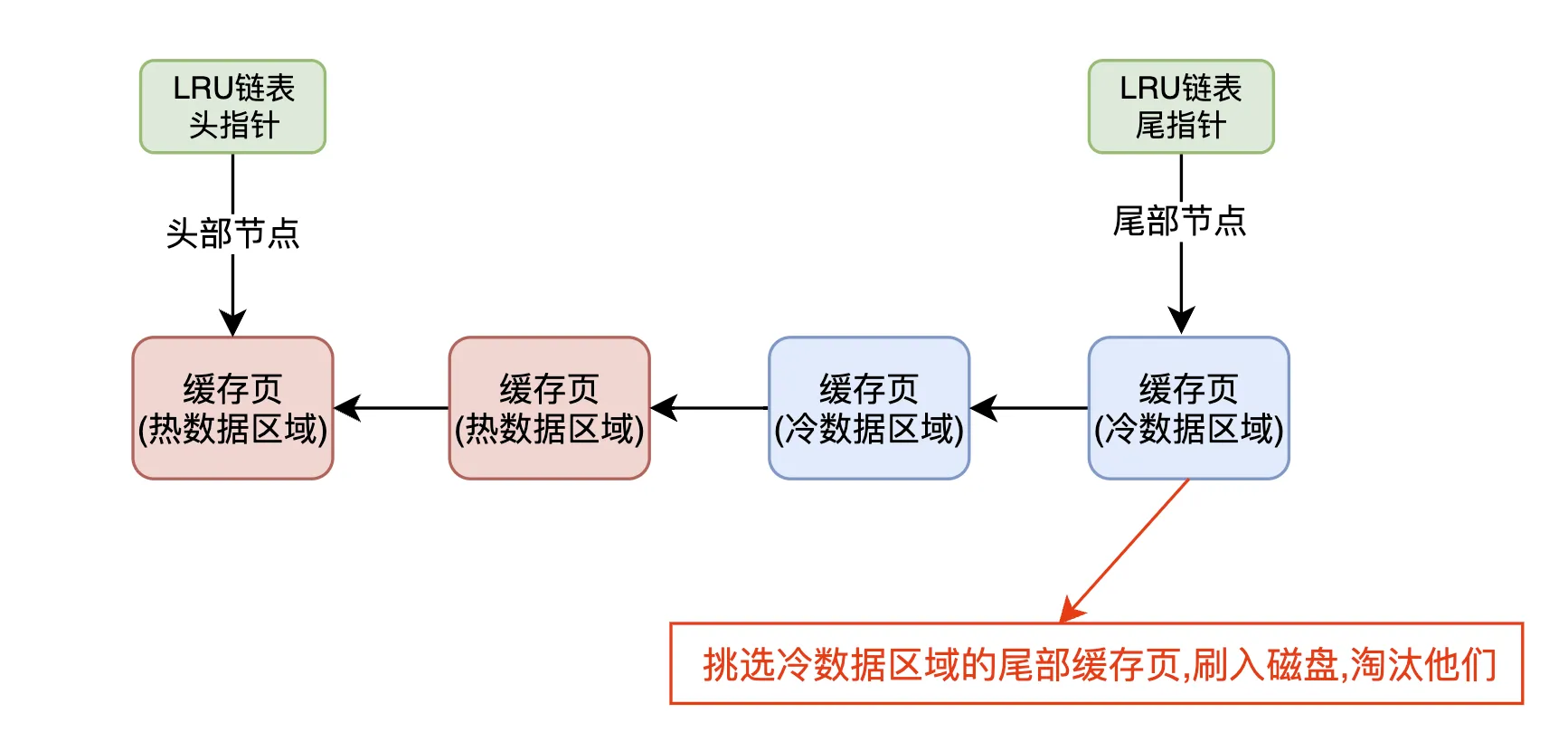
冷数据区域淘汰机制
定位冷数据区域尾部的缓存页
在LRU链表的冷数据区域,尾部的缓存页是最久未被访问的缓存页,通常这些数据是通过预读或全表扫描加载进来的,但并没有被频繁访问。
冷数据页的淘汰
由于这些尾部缓存页已经超过了1秒没有被访问,并且它们处于冷数据区域,所以它们非常适合被淘汰。
此时,MySQL会选择冷数据区域尾部的缓存页进行刷盘操作,将其从缓存中移除并写入磁盘,腾出缓存空间。
避免热数据区域数据被淘汰
由于冷热数据区域的分离,热数据区域中的缓存页不会受到影响。热数据区域中的缓存页,即使已经存在一段时间,也会由于频繁访问而一直保持在链表的头部,减少被淘汰的概率。
优点
减少缓存命中率下降:通过淘汰冷数据区域的缓存页,确保频繁访问的热数据始终留在缓存中,从而提高缓存的命中率。
提升性能:通过优先淘汰冷数据区域的缓存页,确保系统可以快速响应频繁访问的数据请求,避免频繁磁盘I/O。
总结
当缓存页不足时,MySQL的冷热数据区域分离机制确保了系统可以优先淘汰冷数据,保留热数据,从而保证了缓存管理的高效性,并有效减少了不必要的磁盘I/O。
7. 总结
这就是LRU链表冷热数据分离的一套机制。
通过这些学习,我们已经深入理解了LRU链表的设计机制以及冷热数据分离的原理。
冷数据区域的设计:
当数据页刚被加载到缓存中时,它会首先进入冷数据区域的链表头部。
如果在加载后1秒内没有被访问,它会留在冷数据区域,成为冷数据。
热数据区域的设计:
如果加载后的数据页在1秒之后被频繁访问,它就会从冷数据区域移动到热数据区域的链表头部。
热数据区域中的缓存页如果被访问,也会被自动移动到链表头部,确保最常用的数据始终处于缓存中。
冷热数据隔离的好处:
冷数据区域存储的是加载后很少被访问的缓存页,这样避免了冷数据的缓存占用影响到频繁访问的热数据。
通过这样的设计,缓存淘汰时,优先淘汰冷数据区域中的缓存页,确保热数据始终留在缓存中,提升缓存命中率,减少磁盘I/O操作,保证系统的高效运行。
总结:总结来说,InnoDB通过将LRU链表分为冷热两个区域,优化了缓冲池的管理,有效防止了大量一次性访问的数据占据缓存,同时通过时间延迟和访问频率的判断,确保热区保留的是真正频繁访问的数据。从而提高了缓存的使用效率,减少了不必要的数据淘汰和磁盘I/O操作。淘汰策略优先从冷区尾部开始,维护过程涉及页面的插入、移动和淘汰,具体参数可以调整冷热区的大小和晋升条件。这个思想不仅在数据库中非常有效,在其他缓存系统中同样适用,值得在设计中吸收并应用。
8. 🙋♂️🙋♂️🙋♂️在Redis这样的缓存系统中,如果缓存中同时包含了冷热数据,可能会遇到哪些问题?如何解决
缓存命中率下降
热数据(频繁访问的数据)和冷数据(偶尔或从未访问的数据)混在一起,可能会导致热点数据被淘汰。比如,冷数据占据了大量缓存空间,导致热数据频繁被淘汰,进而降低了缓存的命中率。
缓存资源浪费
冷数据占用缓存资源,却很少被访问,导致有用的缓存空间浪费。而 Redis 的缓存空间有限,如果冷数据被频繁缓存,可能会导致热数据一直无法缓存,甚至被提前淘汰。
性能瓶颈
如果缓存中冷数据过多,频繁的缓存淘汰和加载操作可能会增加 Redis 的负担,影响系统整体性能,特别是当冷数据更新频繁时,会导致 Redis 频繁的内存操作,消耗 CPU 和内存。
内存管理问题
对于 Redis 的内存管理来说,混合冷热数据时,它通常会用 LRU 或 LFU 等策略来淘汰缓存。然而这些策略有时会不理想,因为它们没有充分考虑到冷热数据之间的不同需求,可能导致经常访问的热数据被淘汰,而冷数据反而被长时间保留在缓存中。
如何应用冷热数据隔离思想来优化缓存设计?
针对上述问题,冷热数据隔离的思想可以帮助我们优化 Redis 的缓存设计。以下是一些可以应用的思路:
为热数据和冷数据设置不同的缓存实例
设计两个独立的缓存层:可以考虑使用两个 Redis 实例,分别用来存放热数据和冷数据。热数据的缓存实例资源可以配置得更大,淘汰策略可以设置得更激进,比如使用 LRU 或 LFU。而冷数据则可以使用独立的实例,内存较小且淘汰策略宽松,减少对热数据缓存的干扰。
使用不同的缓存过期策略
热数据:可以采用较短的 TTL(过期时间),确保热点数据能够及时更新,并且减少对内存的占用。
冷数据:可以设置较长的 TTL,让其保持在缓存中,减少不必要的磁盘访问。
缓存层级设计
在业务系统中,可以通过分层缓存架构来处理冷热数据。例如,Redis 可以作为 一级缓存(热数据),同时使用 二级缓存(冷数据)存储那些不常用的数据。二级缓存可以选择其他缓存系统或磁盘存储来支持冷数据的存储。
4. 动态冷热数据切换
动态调节冷热数据的缓存策略:可以通过监控访问频率,动态调整数据是存放在热缓存中还是冷缓存中。如果某些缓存项的访问频率降低,可以定期将它们从热数据缓存转移到冷数据缓存,反之,热数据访问频繁时可以动态提升它的缓存优先级。
5. 通过 Redis 的 expire 和 LRU 设置更精细的控制
对于冷数据,可以通过 Redis 的 expire 命令为数据设置合适的过期时间,保证它们不会长时间占据缓存。对于热数据,配置更合适的 maxmemory-policy(如 volatile-lru 或 allkeys-lru)来确保它们能够长期保持在缓存中。
总结
冷数据和热数据隔离不仅仅是数据库设计中的有效策略,同样适用于 Redis 等缓存系统中。通过合理的冷热数据隔离,我们可以:
提高缓存命中率,避免热数据被不必要的冷数据占用。
节省内存,确保缓存空间能够最大化地服务于频繁访问的热数据。
提升性能,减少缓存淘汰操作,避免冷数据过度消耗缓存资源。
在缓存设计中,结合冷热数据隔离策略,可以优化 Redis 的使用,提升系统整体的性能和稳定性。这种优化思想不仅适用于 Redis,也可以参考并应用到其他缓存系统中。
9. 🙋♂️🙋♂️🙋♂️ mysql LRU 算法优化核心机制是什么?
MySQL的LRU算法优化核心机制通过冷热数据分离和时间窗口延迟提升策略,有效解决传统LRU算法在全表扫描、预读等场景下的缓存污染问题,提升缓存命中率。以下是具体实现机制:
9.1. 冷热数据分离的LRU链表结构
9.1.1. 链表分区机制
InnoDB将LRU链表划分为新子列表(热数据区)和旧子列表(冷数据区),比例默认约为5:3(由参数
innodb_old_blocks_pct控制)。
热数据区(young region):存放高频访问的缓存页。
冷数据区(old region):存放新加载或低频访问的缓存页。
9.1.2. 中间插入策略
新数据插入位置:新从磁盘加载的页(如全表扫描或预读的页)不会直接插入链表头部,而是插入到冷数据区的头部(即LRU链表的3/8位置)。
目的:避免单次批量操作(如全表扫描)瞬间占据热数据区,导致真正的热点数据被淘汰。
9.1.3. 优化效果与参数调节
解决的核心问题
预读失效:预读的页若未被实际访问,会停留在冷数据区并快速淘汰,避免占用热数据区空间。
缓存污染:全表扫描加载的页仅在冷数据区短暂停留,不影响热数据区。
关键参数调节
innodb_old_blocks_pct:控制冷数据区占比(默认37%,即3/8位置)。innodb_old_blocks_time:控制冷数据晋升热数据的时间阈值(默认1秒)。
9.1.4. 与传统LRU的对比
9.1.5. 总结
MySQL通过冷热分离和时间窗口验证机制,将临时数据隔离在冷数据区,确保热数据区的高命中率。这种优化本质上是以空间换稳定性,结合参数调节可适配不同业务场景的缓存需求。
10. 🙋♂️🙋♂️🙋♂️ mysql LRU 算法优化 冷区的数据和热区的数据是如何区分的呢?是有两条LRU 链吗? 优先淘汰哪个链的节点?是优先淘汰首节点还是尾节点
在 MySQL 中,LRU(Least Recently Used,最近最少使用)算法用于缓存管理,特别是在 InnoDB 存储引擎的 Buffer Pool 中,用来管理内存中的数据页(Data Page)。MySQL 并没有直接维护两个独立的 LRU 链来区分 热区 和 冷区 的数据,而是通过一个 单一的 LRU 链 来实现对缓存的淘汰管理,通常通过 冷热数据区分 来优化淘汰过程。
如何区分冷热数据区(Hot and Cold Data)?
MySQL 并不显式地将数据分成“热区”和“冷区”两个独立的链,而是通过 访问频率 和 最近使用的时间 来确定数据的“热度”。具体来说:
热数据:指的是在短时间内频繁被访问的数据。通常,这些数据位于 LRU 链的头部。
冷数据:指的是长时间未被访问的数据。通常,这些数据位于 LRU 链的尾部。
LRU 链的工作机制:
MySQL 使用 一个 LRU 链 来管理 Buffer Pool 中的数据页。每当一个数据页被访问时,它会被移到 LRU 链的头部,表示它是“最近使用过”的数据。如果一个数据页长时间没有被访问,它会被保留在链的尾部,表示它是“最久未使用”的数据。
如何执行淘汰?
MySQL 的 Buffer Pool 会根据 LRU 链 来进行内存页的淘汰。具体来说,当内存需要释放空间时,MySQL 会从 LRU 链的尾部 开始淘汰数据。这是因为链尾的节点表示最久未使用的数据,淘汰这些数据可以腾出空间供新的数据页使用。
LRU 链的淘汰过程:
淘汰顺序:LRU 算法会从 链头开始淘汰数据,逐步淘汰最久未访问的数据。
淘汰的节点:每次淘汰时,MySQL 会从链头开始,逐渐淘汰那些长时间未被访问的数据。
LRU 链的优化机制(冷热数据区分的优化):
为了提高性能,MySQL 通过一些优化手段来处理冷热数据:
LRU 近似算法:MySQL 实际上使用了一个 LRU 近似算法,并且根据使用情况动态调整缓存策略。例如,MySQL 会分配一部分 Buffer Pool 用于缓存 热数据,这部分数据会相对较少被淘汰,而另一部分用于缓存 冷数据,这部分数据的淘汰频率较高。
双向链表:MySQL 在实现 LRU 链时,使用了一个双向链表结构。每次数据页被访问时,它都会移动到链表的头部,表示它是最近使用过的数据。链表的尾部则是最久未被访问的数据。
Buffer Pool 的细分:为了优化内存的使用,MySQL 允许在 Buffer Pool 中进行一定的细分管理。通过调节 innodb_buffer_pool_instances 参数,MySQL 可以将 Buffer Pool 分为多个实例,每个实例内都有自己的 LRU 链,从而避免了一个单一 LRU 链中的竞争和性能瓶颈。
总结:
冷热数据区分:MySQL 的 LRU 链通过访问频率和最近使用的时间来区分热数据和冷数据,较频繁访问的数据位于 LRU 链的头部,长时间未访问的数据位于链尾。
LRU 链:MySQL 只使用 一个 LRU 链,并通过这个链来管理数据页的淘汰。热数据会出现在链头,冷数据则位于链尾。
淘汰机制:数据页的淘汰会从 LRU 链的 头部开始,逐步淘汰最久未访问的数据。
MySQL 没有采用两条独立的 LRU 链来区分热数据和冷数据,而是通过智能的缓存和淘汰策略,在一个链中完成冷热数据的管理。
但是 Buffer Pool 可以分为多实例, 每个实例内部有自己的 LRU 链。
评论区