

1. MySQL 运行多事务并发执行的场景
MySQL多线程并发控制: 事务隔离级别、MVCC(多版本并发控制)、锁机制
在我们执行增删改操作时,通常就是将数据页从磁盘加载到 buffer pool 缓存页中,在缓存页进行更新,同时记录 redo log(重做日志)和 undo log(回滚日志)。这些机制应对了两种情况:一种是事务提交之后,若 MySQL 挂掉,则能够通过 redo log 恢复数据;另一种是事务回滚时,通过 undo log 实现数据的回退。
接下来,我们需要进一步提升理解的层次,深入到 事务 的层面。
所谓事务,大家应该或多或少都有一些了解。今天,我们将从 MySQL 内核原理的角度,提升到事务的层面,回顾一下事务的工作原理。
其实,平时我们是否都是在写一个业务系统业务逻辑,逻辑处理完了,业务系统会对数据库执行增删改查操作,是这样的吧?

通常而言,在业务系统中,我们确实是会开启事务来执行增删改操作,用来保证业务逻辑上的事物一致性。比如这个例子:
// 假设使用的是Spring框架的事务管理
@Transactional
public void updateUserInfo(User user) {
// 更新用户信息
userRepository.updateUser(user);
// 假设后续还有其他数据库操作
orderRepository.updateOrderStatus(user.getId());
}在这个例子中,通过 @Transactional 注解来开启一个事务。在事务内,对 user 和 order 进行了两次更新操作。通常,在这种事务内,所有的增删改操作都会在同一个事务中执行,确保这些操作要么全部成功,要么全部失败(即事务回滚)。
在 MySQL 内部,这种事务会涉及到 undo log 和 redo log 机制来确保数据的一致性、持久性以及支持回滚操作。
在业务系统中,通常是按事务执行的,每个事务中可以包含一个或多个增删改查(DML)操作。
事务的基本概念大家应该都了解,就是在一个事务中,所有的SQL语句要么全部成功并提交,要么如果其中一个失败,整个事务就会回滚,所有的更改都会被撤销。

接下来,问题就来了。这个业务系统可不仅仅是单线程的!它需要支持多个线程来处理并发请求。
因为系统是面向多个终端用户的,可能有大量用户同时发起请求,所以系统需要用多个线程来处理这些并发请求。
因此,这个业务系统通常会基于多线程并发的方式,来同时执行多个事务并与MySQL数据库进行交互。
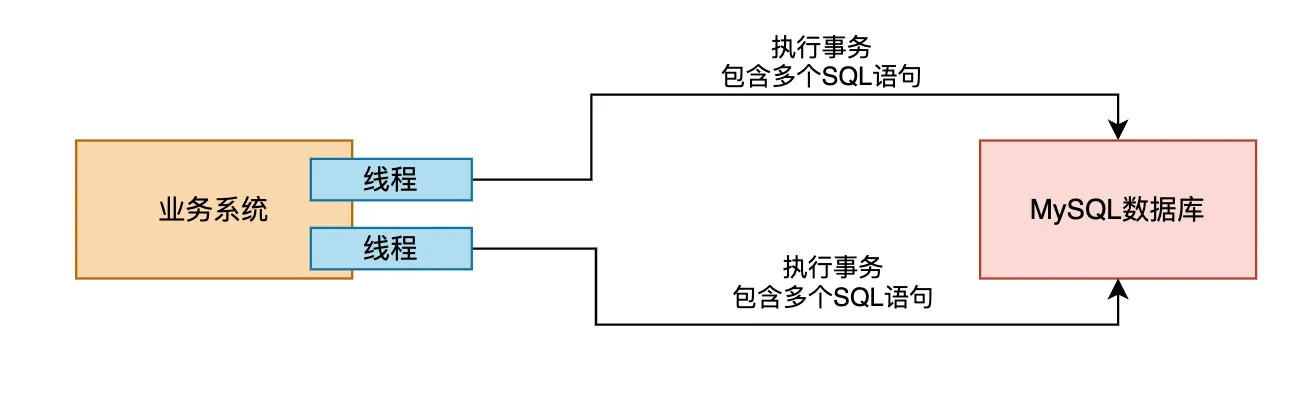
那么,每个事务中的多个SQL语句是如何执行的呢?
其实,执行的原理和之前讨论的内容是一致的。
具体来说,首先会从磁盘加载数据页到buffer pool的缓存页,然后对缓存页进行更新操作。同时,系统会记录相关的redo log和undo log。这样就能保证在事务提交或回滚时,数据的正确性和一致性。
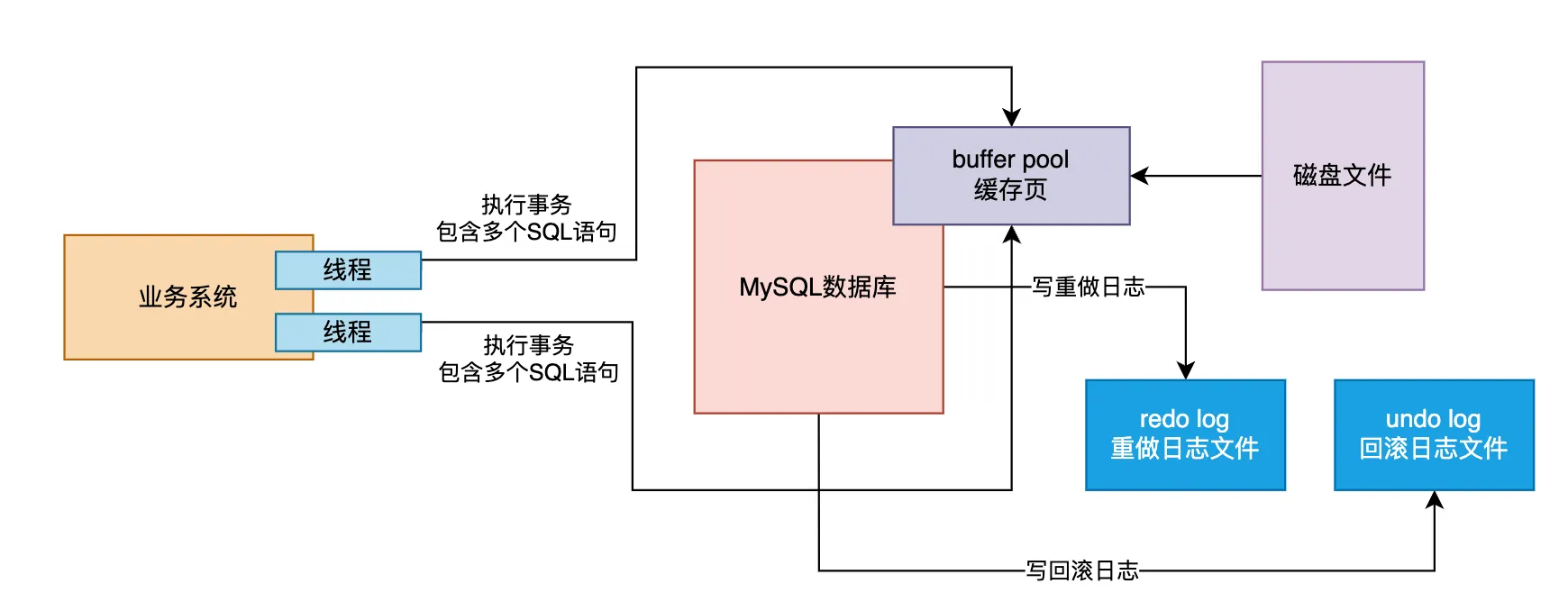
当事务成功提交后,事情就大功告成了。这一过程,我们之前提到过,涉及一些关键步骤,比如在redo log中记录事务提交的标识 [ 🙋♂️🙋♂️🙋♂️ 在redo日志中写入commit标记的意义是什么? ] 等。如果事务提交后,redo log已经刷入磁盘,但MySQL发生宕机,实际上可以通过redo log来恢复事务修改过的缓存数据。
如果是事务回滚,那么只需要依赖undo log进行回滚操作,把之前对缓存页所做的修改撤回,就可以恢复数据到原来的状态。
以上内容是将多个事务与之前讨论的buffer pool、redo log、undo log等机制结合起来的实际操作场景。
然而,在多个事务并发执行时,也会带来一些问题:
当多个事务并发操作时,可能会同时尝试更新缓存页中的同一行数据,这时如何避免冲突?是否需要加锁?
有些事务在更新数据时,另一些事务正在查询该数据,如何解决这些冲突?
接下来,我们将深入探讨如何解决并发事务之间的冲突,特别是对于同时读写、同时写操作的冲突处理机制。我们会介绍MySQL的事务隔离级别、MVCC(多版本并发控制)以及锁机制等相关内容。
2. 多个事务并发更新查询出现的问题
对于业务系统访问数据库时,通常会涉及多个线程并发执行多个事务。对于数据库而言,这就意味着多个事务同时在执行,且可能会有多个事务同时对同一条数据进行更新或查询。在这种情况下,数据库需要解决一些并发访问的问题,确保数据的一致性、隔离性和正确性。
每个事务都会执行增删改查的操作,这就意味着,每个事务在执行对应的 SQL 逻辑的时候,都会 加载磁盘上的数据页到buffer pool缓存中,然后对缓存页进行更新,同时记录 redo log和 undo log,最后执行事务提交或回滚。并且多个事务往往会并发执行这些操作。
当多个事务同时更新或查询缓存页中的同一条数据时,可能会引发主要包括 脏写、脏读、不可重复读、幻读四种情况。
3. 脏写
脏写指的是两个事务(事务A和事务B)同时更新同一条数据。事务A先将数据更新为A值,紧接着事务B又将数据更新为B值。由于事务A的修改还没有被提交,事务B的更新覆盖了A的修改,可能导致数据丢失或不一致的情况。
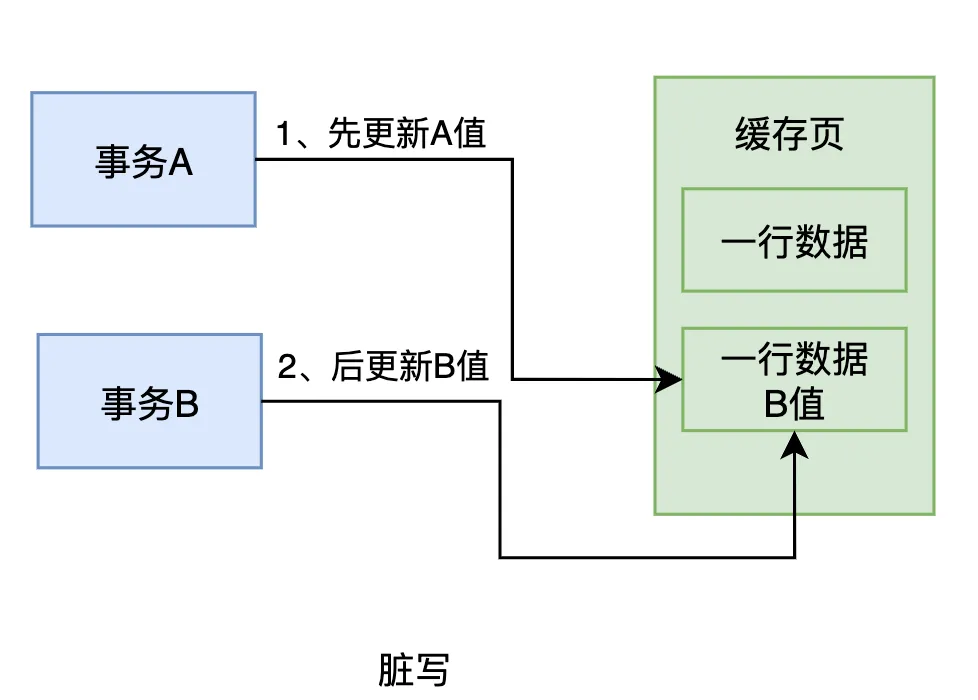
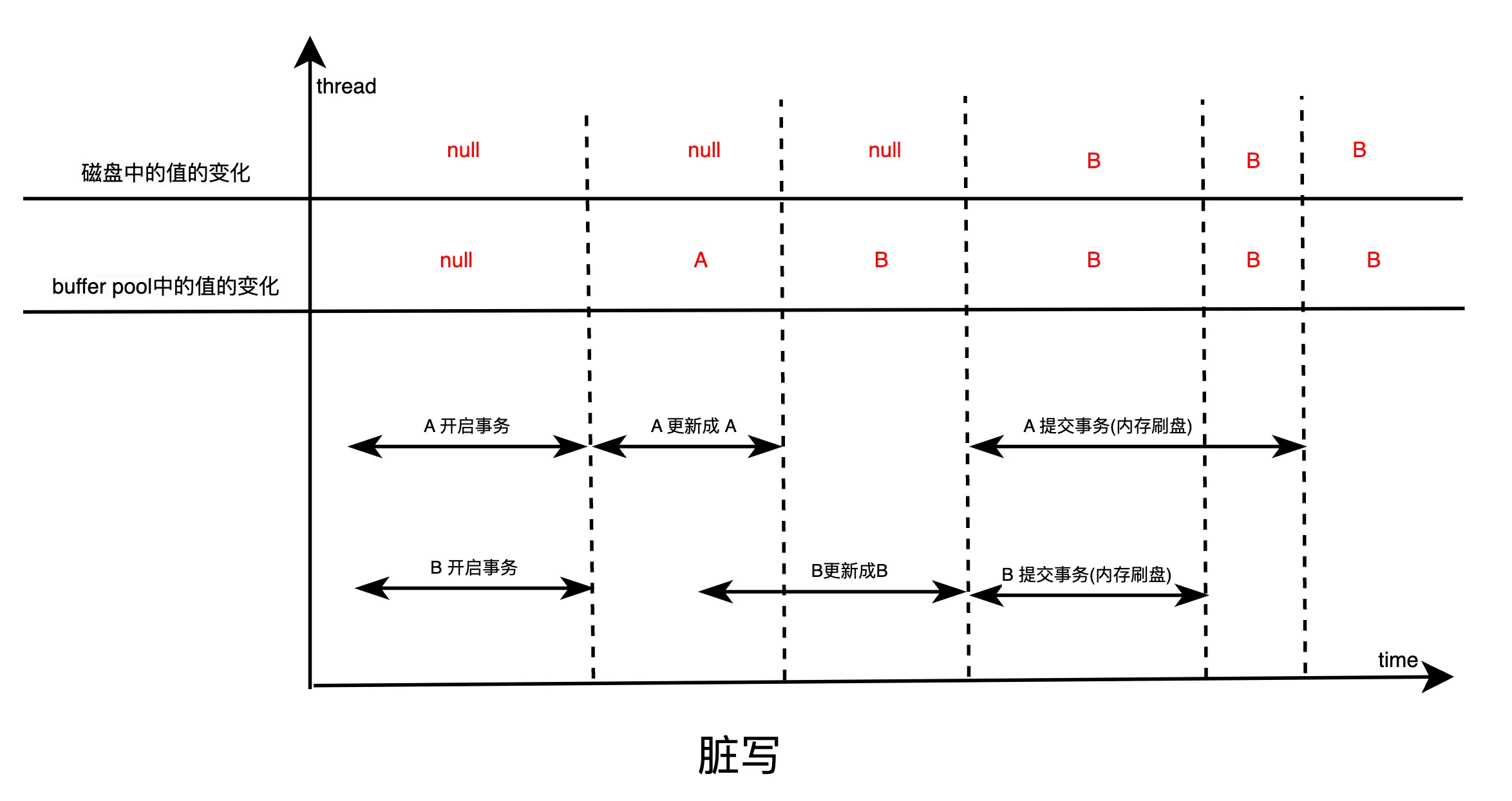
在这种情况下,事务B先更新了数据为B值,而事务A的更新记录了一个undo log,表明事务A在更新前那行数据的值为NULL。当事务A回滚时,会基于其undo log将数据回滚为NULL,这意味着在事务A回滚之后,这行数据的值变回了NULL。
这里的问题在于,虽然事务B已将数据更新为B,但由于事务A回滚,事务B的更新可能会丢失。最终的数据状态不一致,事务A回滚的操作影响了事务B的结果,导致脏写的发生。
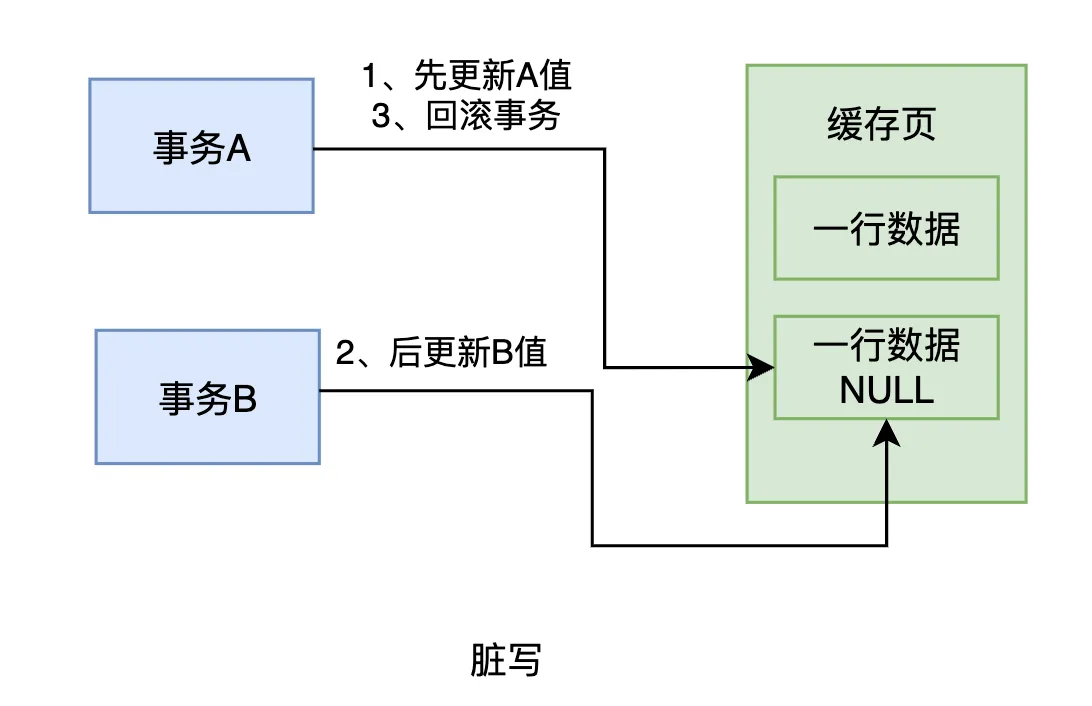
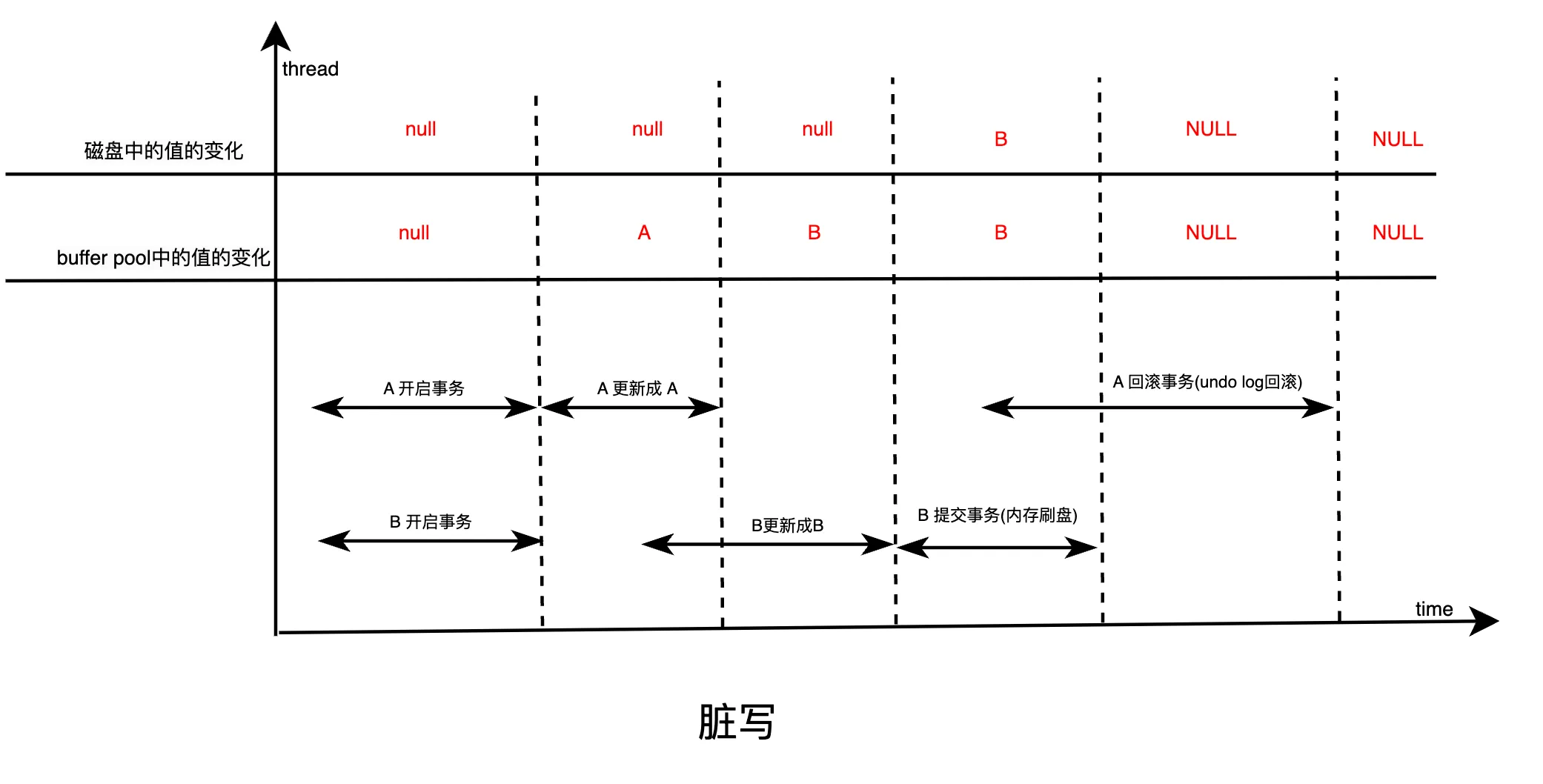
此时,事务B会觉得非常困惑,因为它明明已经更新了数据,将其值改为B,但由于事务A回滚了,导致B的更新被覆盖,数据又回到了原来的状态。这种情况对于事务B来说显得非常不合理,因此我们称这种现象为“脏写”。
脏写的本质在于,事务B修改了事务A已经修改过的数据,而事务A尚未提交。由于事务A可能随时回滚,它的更改并未持久化,因此事务B的更新会被回滚,造成事务B的修改丢失。这就是脏写的典型例子。
4. 脏读
假设事务A已经更新了数据并将其设置为A值,此时事务B查询这行数据,看到的值应该是A值,因为事务A已对数据进行了修改,而事务B的查询是基于当前事务的视图。
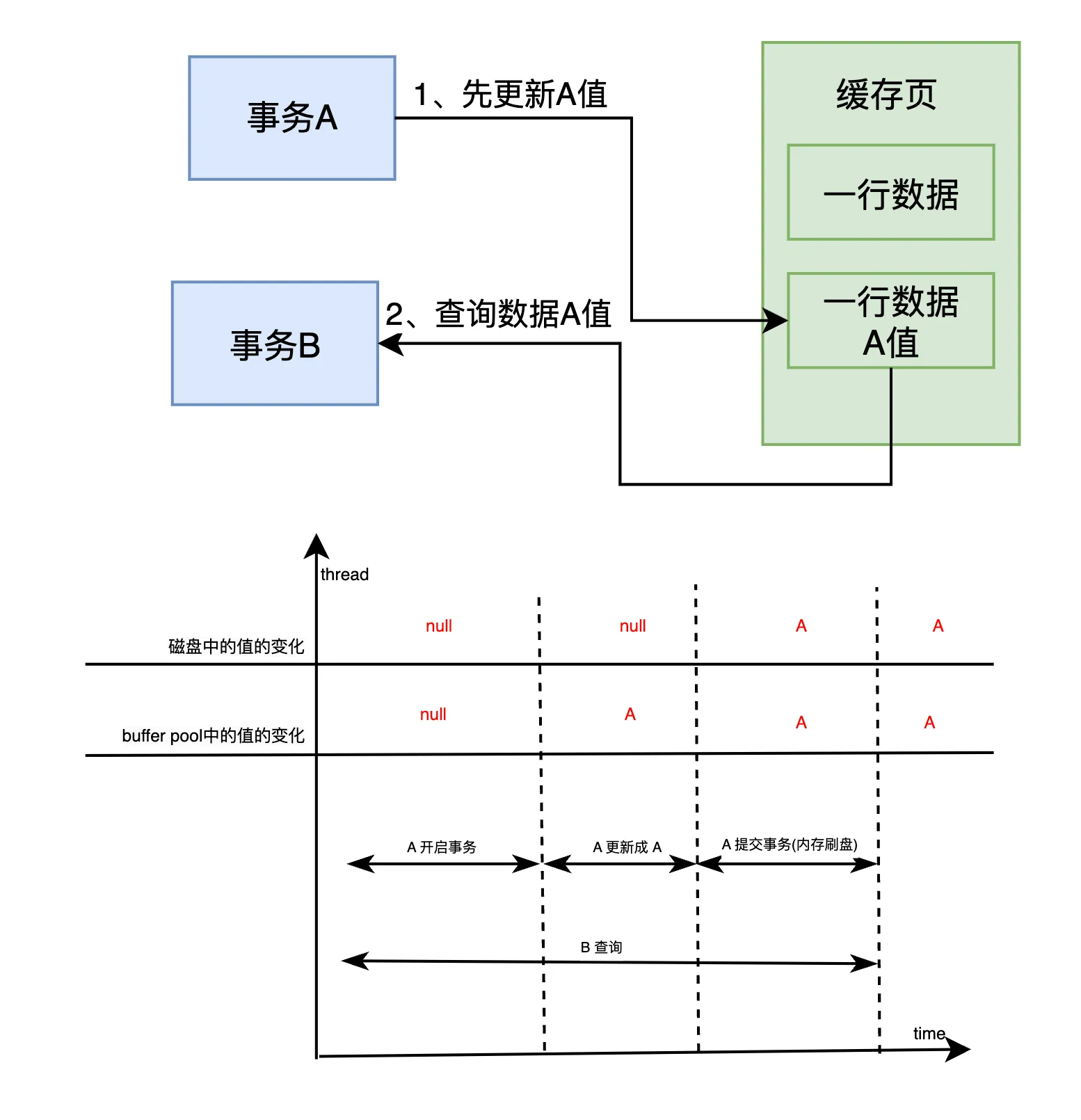
这时,事务B的问题就来了。因为事务A回滚了,原本被事务A更新为A值的数据又恢复成了NULL值。而事务B在执行业务处理时,依赖的是事务A修改后的A值,但由于事务A回滚,导致事务B在后续使用这个数据时出现了不一致的情况。事务B看到的仍然是A值,但实际上数据已经被恢复为NULL了,这就会导致业务处理中的逻辑错误。
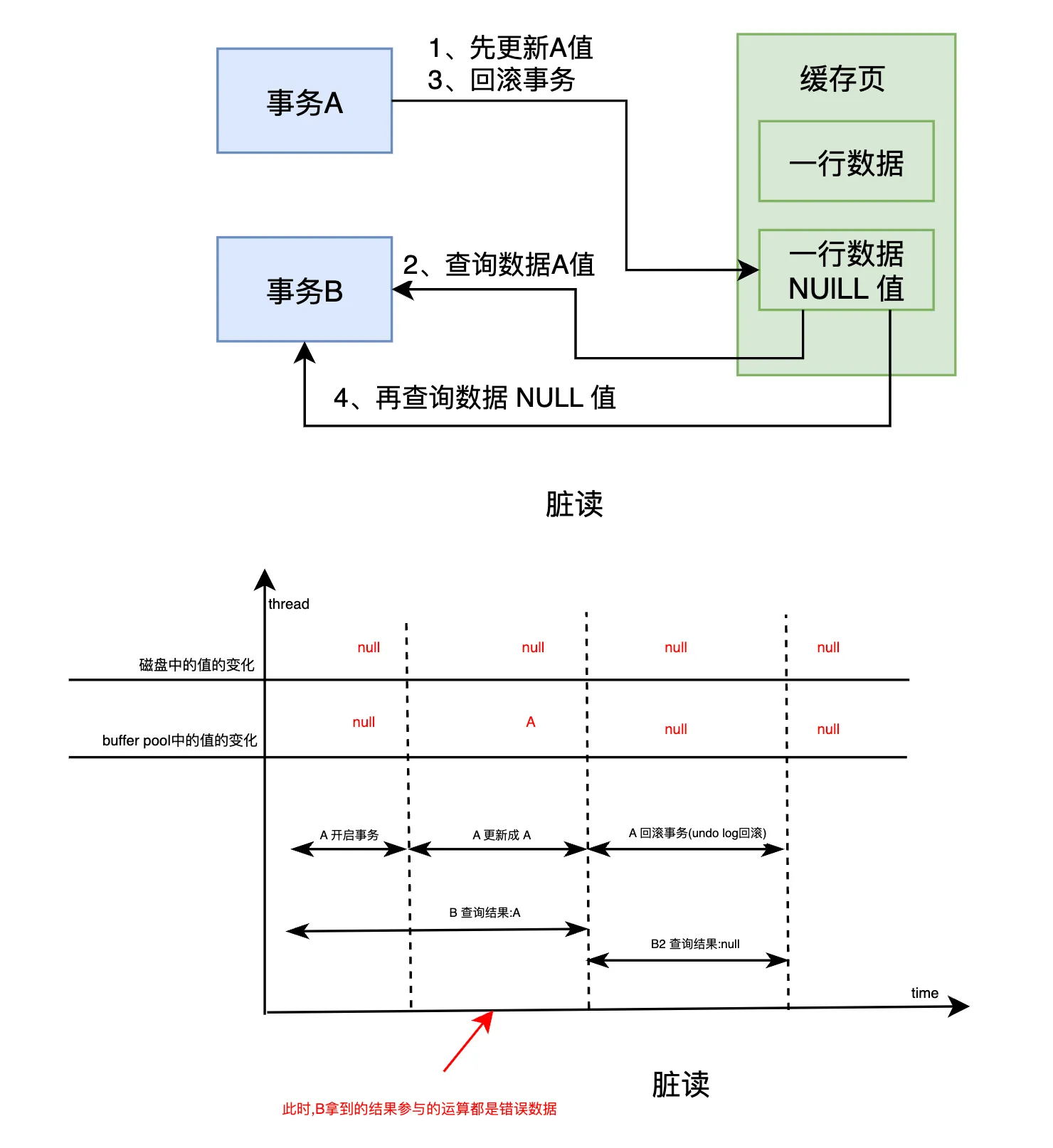
所以,脏写和脏读的本质都在于事务A和事务B之间的操作冲突。脏写发生在事务B修改了事务A修改过的数据,而事务A尚未提交,因此事务A随时可能回滚,导致事务B修改的结果丢失。而脏读则是事务B读取了事务A修改的数据,但由于事务A未提交,导致事务A可能会回滚,最终事务B查询到的数据变得不一致。
简单来说,这两者的共同点就是:一个事务操作了另一个事务尚未提交的数据,这种不确定性可能导致数据的丢失或不一致,从而引发问题。
再总结一下:上面, 我们讨论了当多个事务并发执行,并且对 MySQL 缓存页中的同一行数据进行更新或查询时,可能会遇到的脏写和脏读问题。
我们已经明白,这些问题的根源在于:一个事务读取或修改了另一个事务尚未提交的数据,而该事务随时可能回滚,导致数据状态发生变化,从而引发问题。
下面, 继续探讨并发事务执行时可能遇到的另外两种情况:不可重复读 和 幻读。这两种问题相对来说更特殊一些~~~
5. 不可重复读
不可重复读 主要发生在这样的场景:
假设 事务 A 在执行过程中,需要多次查询同一条数据。而与此同时,事务 B 和 事务 C 也在对这条数据进行更新。
为了避免 脏读,我们先设定一个前提:事务 A 只能在事务 B 提交后,才能读取到事务 B 修改后的数据。换句话说,如果事务 B 还未提交,那么事务 A 读到的依然是事务 B 修改前的旧数据。
这个设定避免了脏读,因为 脏读 发生在事务 A 读取到事务 B 未提交 的修改,而一旦事务 B 回滚,事务 A 就会发现数据变回原来的值,导致数据不一致。
但避免了脏读,并不意味着一切就此太平无事,不可重复读 的问题随之而来。
例如,假设 MySQL 缓存页 中某条数据的初始值是 A 值,此时 事务 A 启动后第一次查询这条数据,读取到的就是 A 值,如下图所示。
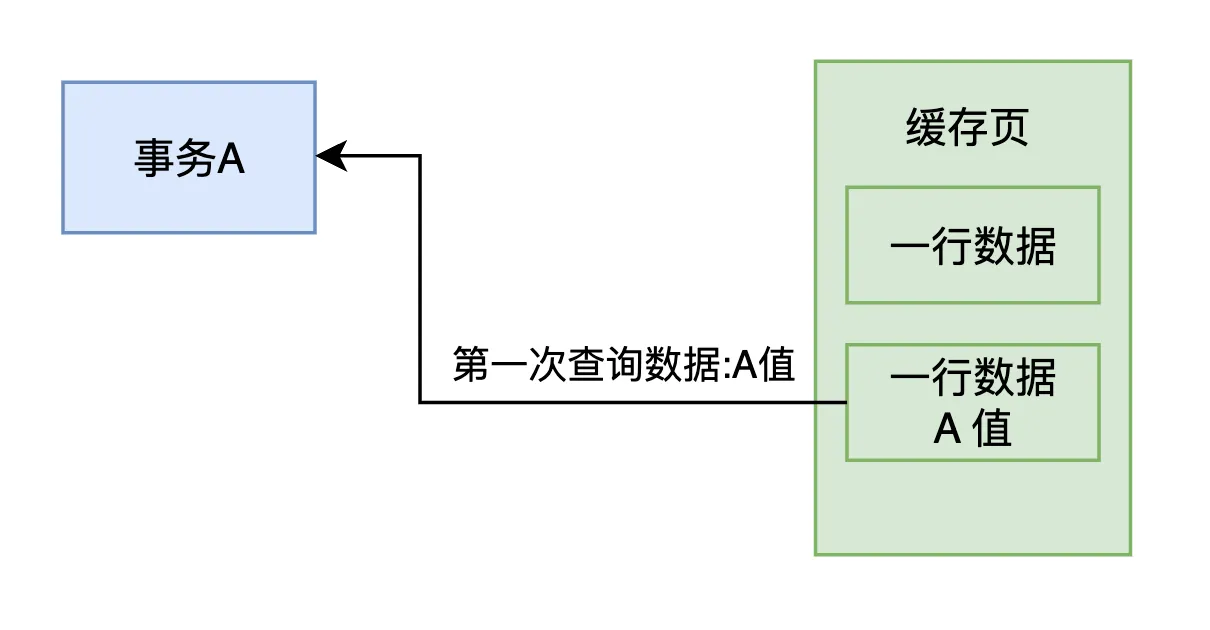
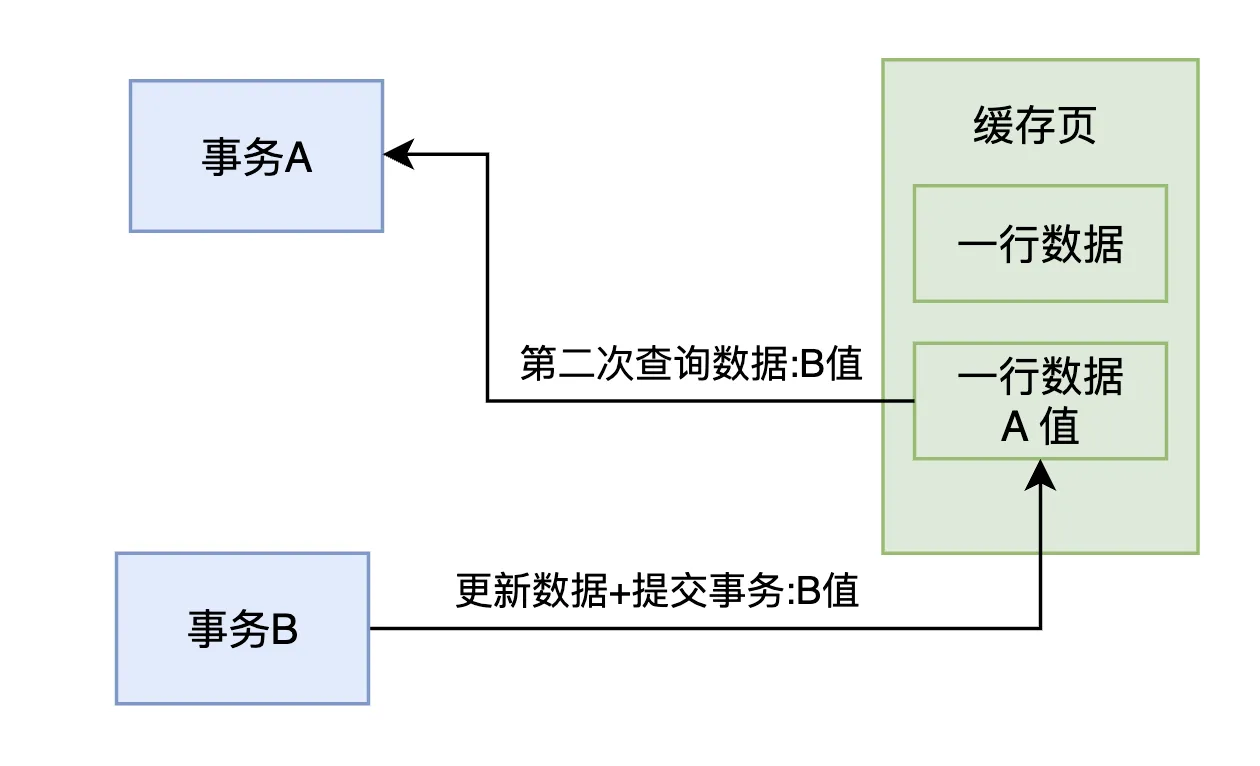
接着,事务 B 更新了该行数据的值为 B 值,并且 立刻提交 了。此时,事务 A 仍然没有提交,但它在事务执行期间再次查询这条数据时,读取到的是 事务 B 修改后的 B 值,因为事务 B 已经提交 了,所以事务 A 可以读取到最新的 B 值。
也就是说,事务 A 在同一个事务内,对同一条数据进行了两次查询,却得到了不同的结果——第一次查询得到 A 值,第二次查询得到 B 值。
这个现象就是 不可重复读,它的本质是 同一个事务内的多次查询结果不一致,原因是 在事务执行的过程中,其他事务提交了对同一条数据的更新,导致事务 A 读到不同的结果,如下图所示。
接着,事务 C 又更新了这条数据的值为 C 值,并且 提交了事务。此时,事务 A 仍然没有提交,但它在事务执行期间 第三次查询 这条数据时,读取到的是 事务 C 修改后的 C 值。
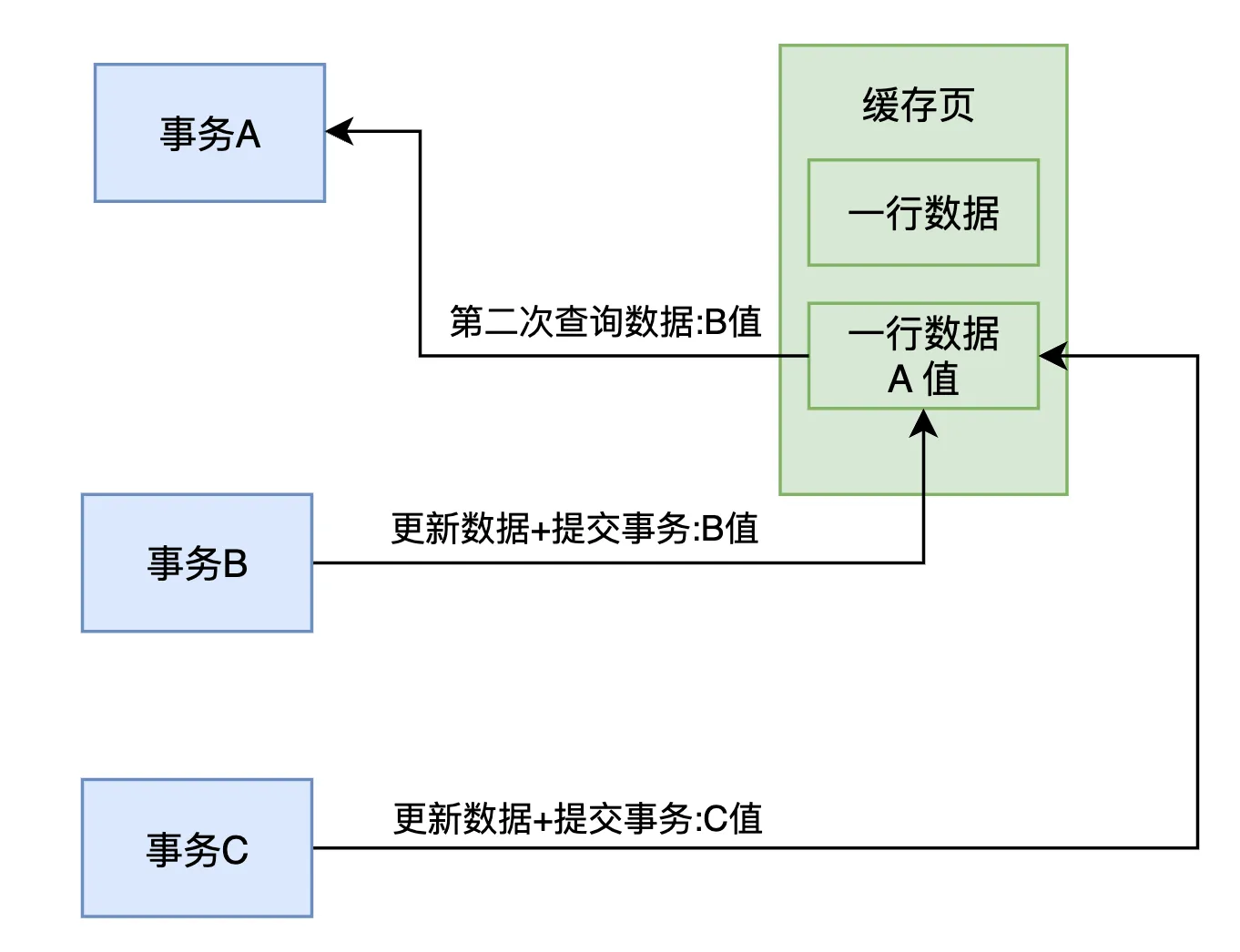
这样一来,事务 A 在同一个事务内,连续三次查询同一条数据,却得到了不同的结果:
第一次查询 读到 A 值
第二次查询 读到 B 值
第三次查询 读到 C 值
这就是 不可重复读(Non-Repeatable Read)问题的典型表现:在同一个事务中,多次查询相同的数据,结果却因为其他事务的提交而发生变化,导致事务 A 无法保证查询结果的一致性。
不可重复读 这个问题本质上取决于 你的预期 和 数据库的事务隔离级别。
• 如果你的业务逻辑允许 在同一个事务中多次查询同一条数据,每次都能获取最新提交的值(即事务B和事务C修改并提交后的值),那就不会把这个情况视为问题。
• 但如果你的期望是 在事务A执行期间,无论其他事务如何更新并提交数据,你都希望 始终读取到事务A第一次查询时的值,那么当数据库返回了更新后的值时,就会认为 出现了不可重复读问题。
总结:
不可重复读的本质在于:是否允许在同一个事务中,不同时间点查询到不同的结果。如果你的需求是事务内部查询的值必须一致,那么当数据库未满足这个需求时,你就会认为这是一种问题,也就是 不可重复读。
不可重复读的定义
不可重复读,简单来说,就是同一个事务内,多次读取同一条数据,可能会得到不同的结果,而这是由于其他事务提交了对这条数据的修改导致的。
理解重点:
前提:事务A要多次查询同一条数据。
关键:在事务A的执行期间,其他事务(如事务B、事务C)对这条数据进行了更新并提交。
结果:事务A在不同时间点查询这条数据时,得到了不同的结果。
是不是问题?
如果你的业务不要求可重复读(比如你就是想要读到最新的数据),那不可重复读对你来说 不是问题。
但如果你的业务逻辑要求事务内查询的结果必须一致,即 第一次查询的数据是什么,后续查询时数据就不能变,那么不可重复读 就是问题,需要通过 更严格的事务隔离级别(如可重复读) 来解决。
6. 幻读
我们来继续聊聊数据库并发问题的最后一种情况——幻读。听起来好像挺吓人,仿佛是某种神秘的魔法现象,对吧?
其实幻读并没有那么神秘,我们来详细解析一下。
简单来说,假设有一个事务A,执行了一条SQL语句,其中包含一个查询条件,比如 SELECT * FROM table WHERE id > 10。
事务A首次执行这条查询语句时,查询结果中返回了10条数据,如下图所示。
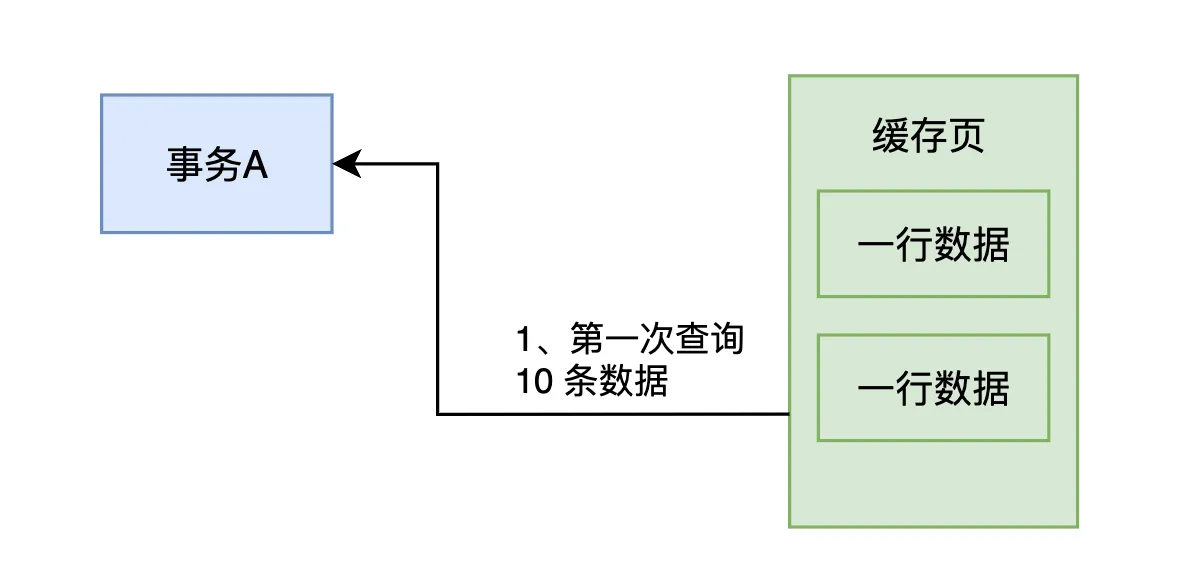
接着,假设此时有另一个事务B插入了几条数据到表里,并且事务B已经提交了,如下图所示。这样一来,表中就多了几条数据。
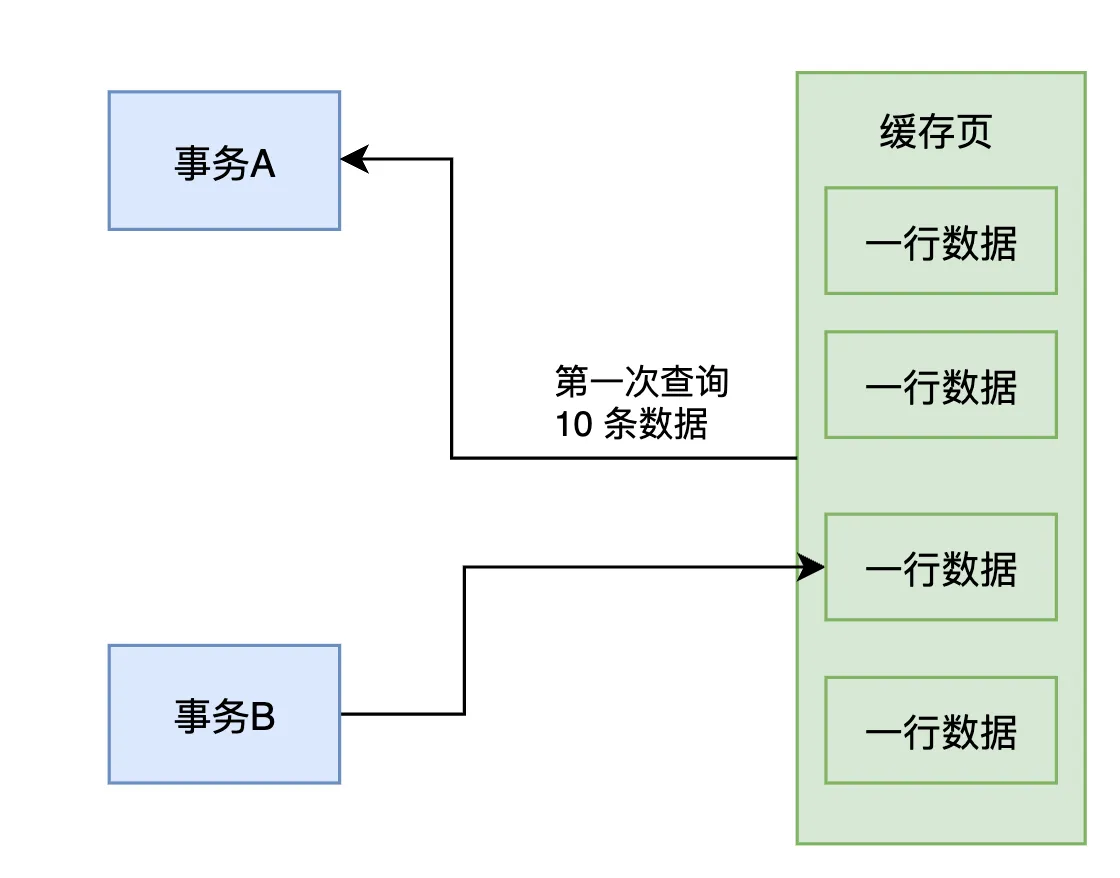
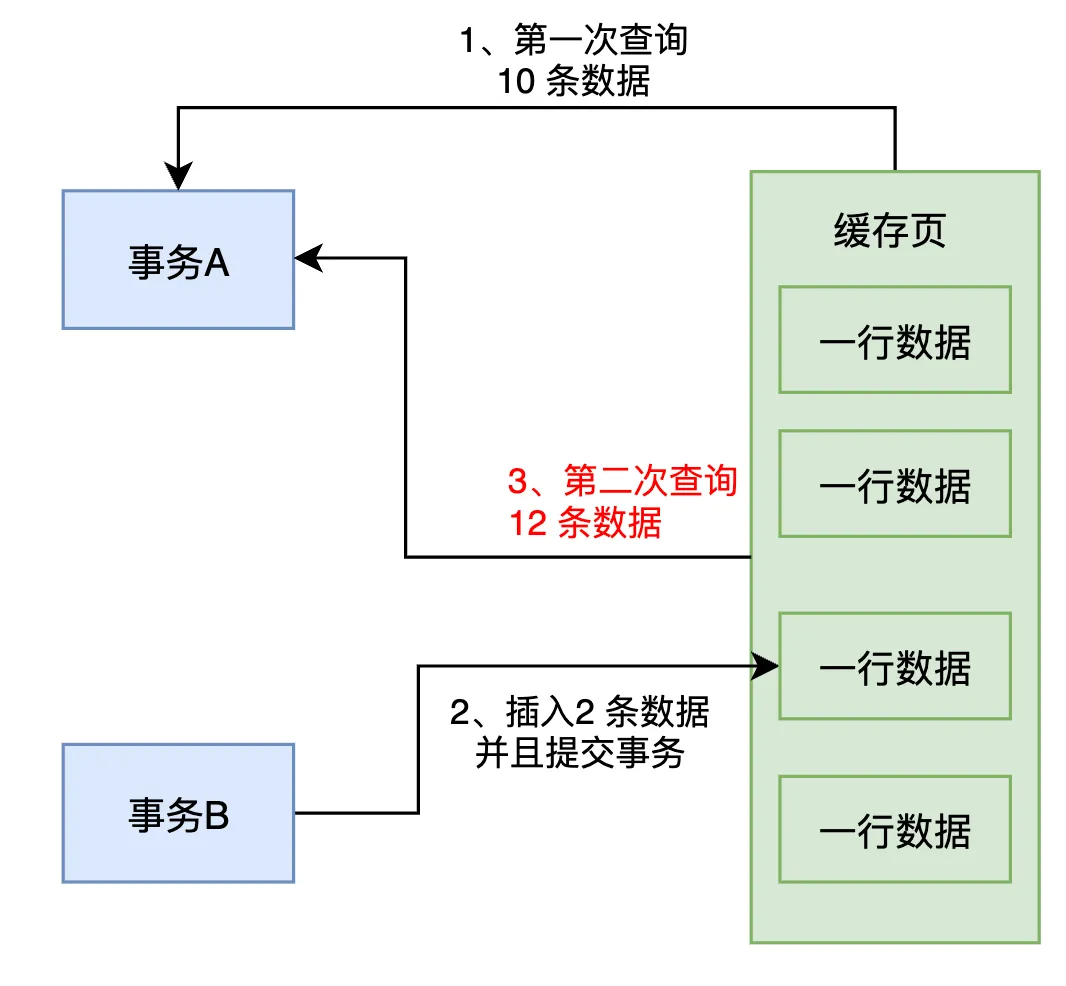
接着,事务A在第 二 次查询时,按照之前完全相同的条件执行了“select * from table where id>10”这条SQL语句。由于事务B插入了几条数据并提交,导致这次查询的结果从原本的10条增加到了12条数据。
7. 总结
幻读问题的关键在于,事务A在执行多次相同的SQL查询时,每次查询结果却不一样。第一次查询结果是10条数据,但第二次查询时却是12条数据,因为其他事务(比如事务B)插入了新数据,并且提交了。事务A因此看到了一些在之前查询时并没有看到的新数据,这种现象被称为幻读。
脏写、脏读、不可重复读、幻读这些问题,都是由于多线程并发执行事务引起的。在多事务并发的情况下,不同的事务会对缓存中的相同数据进行增、删、改、查操作,这种并发行为可能导致这些并发问题。因此,为了解决这些并发问题,数据库采用了事务隔离机制、MVCC多版本控制机制以及锁机制等一整套解决方案,确保事务的独立性和数据的正确性。
深入理解这些原理后,我们将进一步探讨数据库的优化实践案例。通过这种方式,大家能够全面了解数据库内部的执行机制,就像理解JVM原理后,能够对JVM进行更有效的优化一样。
评论区